
GCP에서 Datawarehouse Governance 구축하기(feat. BigQuery) 2편
Introduction
지난 GCP에서 Datawarehouse Governance 구축하기 1편(링크)에서는 간략하게 Datawarehouse solution으로 BigQuery를 도입한 이유와 어떻게 Project structure, Security(IAM, Audit, VPC), Monitoring 부분을 설계하고 구현했는지를 함께 살펴봤습니다. 1편에서는 주로 BigQuery의 Governance보다는 BigQuery를 중심으로 한 Network, Security, Permission과 같은 Datawarehouse의 Governance에 대해서 다뤘다면, 2편은 BigQuery 자체의 Resource를 어떻게 효율적으로 사용할 것인지와 Data Warehouse 전체 Infra resource에 대한 관리를 어떻게 하고 있는지를 다룰 예정입니다.
이번 글에서 다룰 부분은 아래의 부분과 같습니다.
- Performance
- Table Modeling
- Partitioning & Clustering
- Table Schema Management
- BigQuery Client
- Schema Project
- Resource Management
Performance
저희가 고려한 Performance 두 가지 종류의 Performance입니다.
- 사용자의 Performance → Table Modeling
- BigQuery의 Performance → Partitioning & Clustering
사용자의 Performance를 높이기 위해서 Table Modeling부분을, BigQuery의 Performance를 높이기 위해서는 Table Modeling, Partitioning & Clustering을 활용했습니다.
Table Modeling
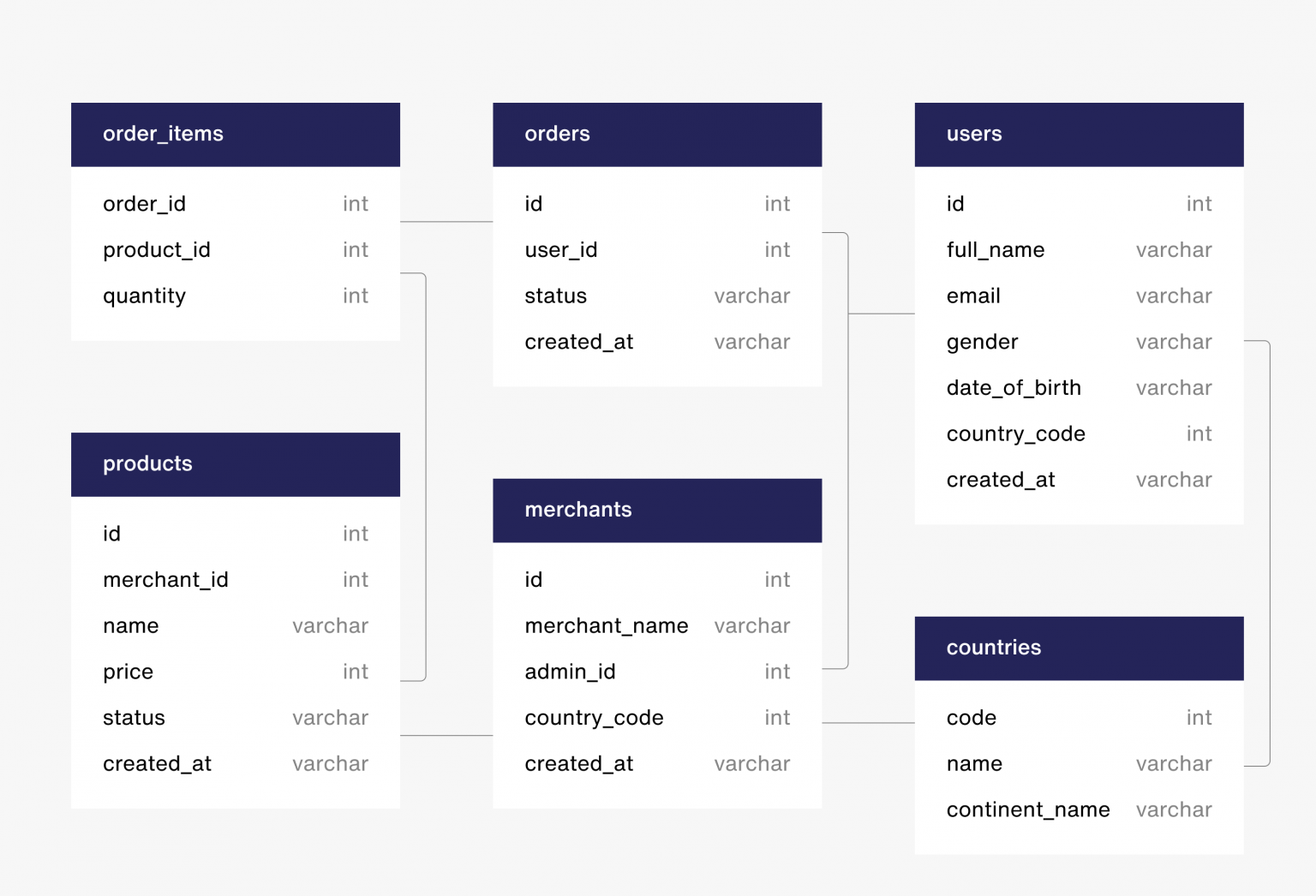
Table Modeling에서 가장 신경 쓴 부분은 Column과 Table 이름의 표준화 작업과 join-key 설계 입니다.
데이터의 표준화
각 개발팀에서 만든 Table들의 데이터를 확인해보면 같은 의미의 데이터이지만 Column의 이름이 모두 다릅니다.
예를 들면, Sendbird Application의 id는 아래와 같이 나뉘어 있었습니다.
- application_id
- app_id
- crm_application_id
이외에도 많은 파편화 된 이름들을 ETL시 표준화 작업을 통해 통일시켜서 사용자들이 더 쉽게 데이터를 사용할 수 있도록 하였습니다.
Key Denormalization
데이터들이 기본적으로 상위 키까지 포함함으로써 BigQuery에서 비효율적인 Join 작업을 줄이도록 하였습니다. 이는 BigQuery의 효율성뿐만 아니라 사용자들도 여러 테이블을 조인하지 않고 쉽게 metric을 뽑을 수 있게 만듭니다.
예를 들면, Sendbird에서는 Organization(회사)라는 객체는 여러 개의 Application(서비스)을 가지고 있습니다. 기존에는 Application의 metric 데이터라고 하면 application의 id만 가지고 있어서 organization level로 aggregate를 위해서는 metric → application → organization 이렇게 3개의 테이블이 필요했다면 metric에 organization key를 바로 넣음으로써 바로 application level의 데이터에서 organization level의 metric을 만들 수 있게 됐습니다.
Partitioning & Clustering
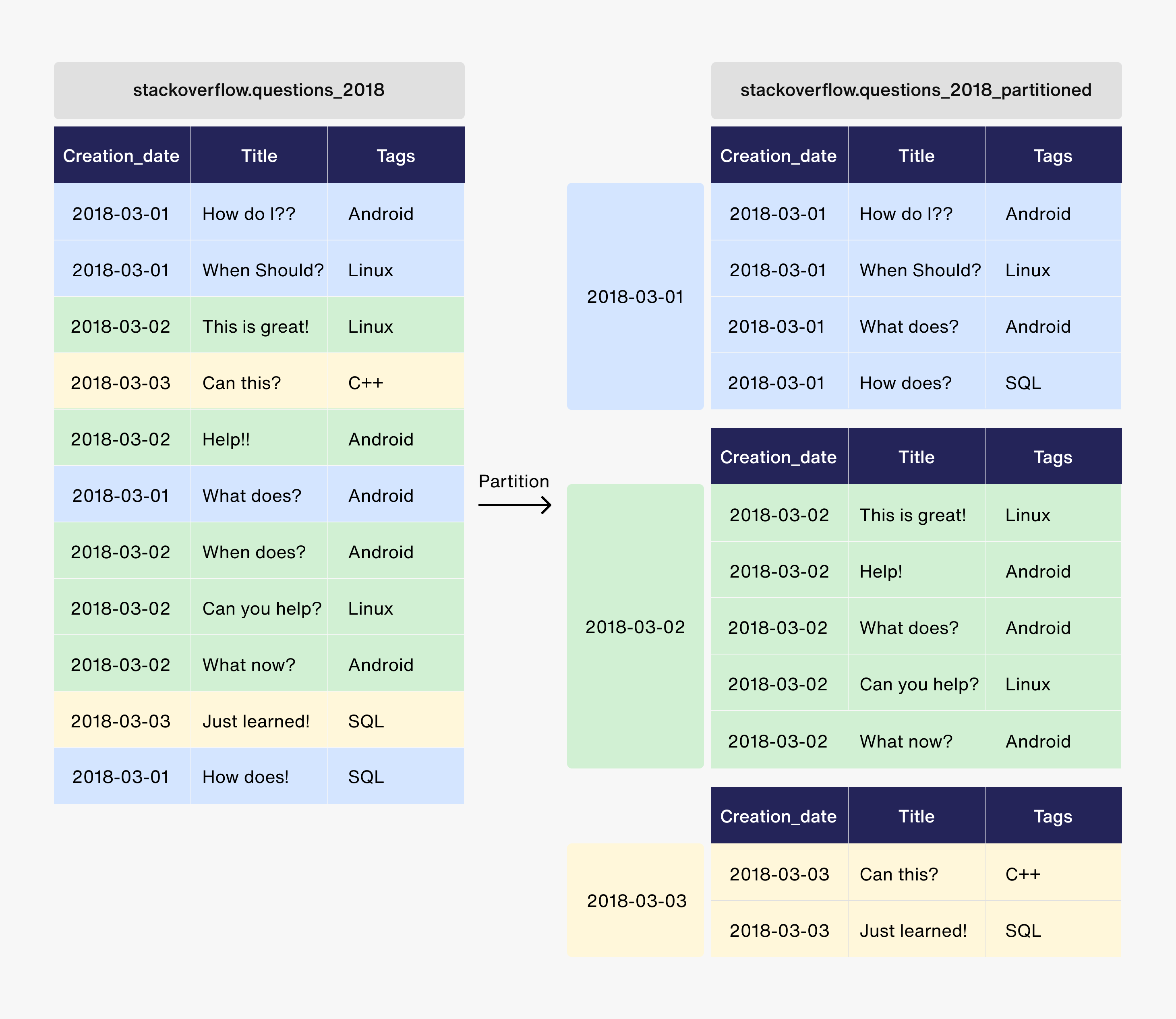
데이터베이스를 효율적으로 사용한다는 것은 되도록 필요한 데이터만 Scan 하는 것입니다.
대부분의 RDBMS는 이를 위해서 Partitioning과 Index를 사용하고 있습니다.
BigQuery에서도 이를 위해서 Partition key, Cluster key feature를 제공하고 있습니다. 기존 RDBMS와 다른 부분은 Cluster key를 하나만 정의 할 수 있다는 점입니다. (보통 RDBMS는 여러 개의 Index를 생성하는 것과 차이가 있습니다.)
BigQuery에서는 하나의 Partition key와 Clustering key를 생성할 수 있기 때문에 신중하게 이를 생성해야 합니다. Sendbird에서는 아래 두 부분을 기초하여 설정하였습니다.
- Cardinality
- Common Case Fast
아시는 것처럼 Cardinality는 고유성이고, Common Case Fast는 가장 흔한 경우를 빠르게 하라는 것입니다.
아무리 Cardinality가 높아도 filter로 사용하지 않는 column이라면 의미가 없고, 아무리 자주 사용하더라도 cardinality가 너무 낮은 경우도 의미가 없습니다.
또, 하나의 규칙으로는 시계열 데이터에 대해서는 resolution 별로 일정한 partition key와 clustering key를 설정하였습니다. 이를 통해서, 사용자는 Table을 파악하지 않더라도 where 절에 시간과 관련된 filter를 넣으면 효율적으로 데이터를 찾을 수 있다는 생각을 하게 됩니다.
Sendbird에서는 각 resolution별로 아래와 같이 공통으로 Partitioning을 적용했습니다. (Partitioned Table의 개수 제한: 4,000)
- Daily 이하 resolution의 Data → Daily Partition
- Monthly resolution의 Data → Monthly Partition
예를 들어 어떤 application의 timeseries의 log data는 아래와 같이 설정하였습니다.
- Partitioned on field: timestamp
- Clustered by: timestamp, app_id
Partition key뿐만 아니라 cluster key도 같이 생성함으로써 partitioned table 내에서도 필요한 부분만 데이터를 읽을 수 있도록 설계하였습니다.
Table Schema Management
위에서와같이 규칙을 만들고 유지하기 위해서는 Table을 Schema를 리뷰가 가능한 상태로 효율적으로 관리할 수 있어야 합니다. 이를 위해서 Schema의 Life cycle을 코드로 관리해야겠다고 생각을하였고 이를 위해서는 schema 변경을 위한 Client와 이 Client를 사용한 변경 사항을 관리하는 Repository가 필요했습니다.
BigQuery DDL Client
현재 GCP에서 제공하는 BigQuery client는 아래와 같은 DDL을 지원하지 않습니다.
- Rename column
- Modify column’s data type
- Remove column
예를 들면, ‘example’ table의 ‘test’ column을 ‘test2’로 rename 하기 위해서는 다음과 같은 과정이 필요합니다.
- rename된 column이 적용된 새로운 schema Table인 ‘example_new’을 생성.
- SELECT * except(‘test’), test as test2 from example 쿼리를 Destination Table을 ‘example_new’로 설정한 후 실행.
- ‘example’ Table을 삭제.
- 새로운 Schema(rename이 적용된)로 example Table 생성.
- ‘example_new’ Table의 데이터를 ‘example’ Table로 copy.
- ‘example_new’ Table을 삭제.
이와 같은 작업을 manual로 진행하는 것은 작업의 기록을 남기기도 어렵고, Human Error에 취약합니다.
그래서 위와 같은 DDL Operation이 지원하기 위해서 기존 Client를 wrapping해서 DDLClient를 만들었습니다. 새로운 operation 지원 외에도 환경별로 partitioning을 적용하는 부분을 overriding할 수 있는 부분 등을 지원할 수 있게 되었습니다.
Schema Management Repository
Repository를 이용해서 Schema의 Change를 apply할 때 PR Request를 통해서 리뷰 받고 적용하게 됩니다.
하나의 간단한 팁으로 PR Request Template을 통해서 위에서 정의한 Naming Rule, Partition&Cluster key정책 등을 쉽게 확인하고 이를 기준으로 리뷰할 수 있게 하였습니다.
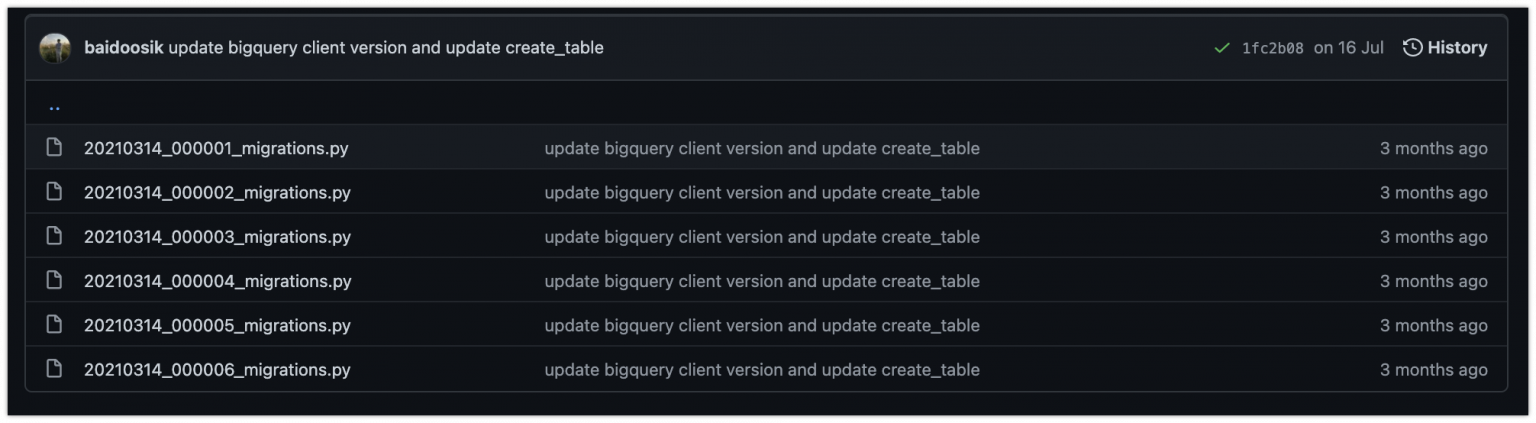
위와 같이 각 Project의 Dataset마다 schema change 이력을 관리함으로써 Table을 변경 history를 남길 수 있게 되었습니다. 실제 table resource에는 몇 번 migration file까지 적용되어 있는지 tag가 있어서 client library에서 이를 확인해서 순서를 보장해주게 됩니다.
Resource management
Sendbird에서는 AWS, GCP, Datadog 등 대부분의 Infrastructure를 Terraform으로 관리하고 있습니다. Datawarehouse Governance를 만들기 위한 Infra 역시 Terraform으로 생성하고 관리하였습니다.
Infra를 코드로 관리하는 것에 대한 장점은 아래와 같습니다.
- 문서화: 모든 인프라를 코드로 기록하기 때문에 인프라의 구조를 파악하기 쉽습니다.
- 자동화: 매번 수동으로 만드는 것이 아니라 코드를 통해서 적용하므로 자동화가 가능해집니다.
- 안전성: 수동으로 만들 때 발생하는 Human Error를 방지할 수 있습니다.
- 형상 관리: 코드로 관리하기 때문에 인프라의 변경 기록을 관리할 수 있습니다.
- 리뷰 및 테스트: GUI로 Resource를 만든다면 매번 리뷰를 받고 적용한다는 것은 불가능하지만 코드로는 가능하기 때문에 실수를 예방할 수 있습니다.
- 재사용성: 똑같은 인프라를 생성하는 것이 아주 간편해집니다.
위와 같은 이유로 Datawarehouse의 대부분의 Resource를 Infrastructure As Code의 대표적인 Tool인 Terraform으로 생성하여 관리하고 있습니다.
마지막으로 각 Resource에 대한 Terraform 코드의 설명보다는 어떻게 directory를 나누었고, 어떤 부분을 module로 만들었는지 설명드리겠습니다.
사용 중인 대략적인 Directory 구조는 아래와 같습니다.
-gcp(service provider)
- organization (organization level resource (ex. vpc-service-control)
- development (projects for development env)
- staging (projects for staging env)
- production (projects for production env)
- modules (module for reuse)
- sb-dw-bi-prod (bi team project)
- sb-dw-calls-prod (calls data and team project)
...
- sb-dw-tp-prod (third-party data project)
- global (global level resource)
- audit (bigquery_logging_project_sink resource)
- iam (IAM resources(iam user, service account, role, etc))
- project (project)
- us (us regional level resource)
- bigquery (bigquery resource ex. dataset)
- storage (storage)
GCP provider안의 resource만 한 번 살펴보면 organization level의 resource와 환경별 project들을 포함하는 directory로 구성되어 있습니다. 그리고 각 환경 안에는 여러 프로젝트로 구성되어 있고, 프로젝트 이름의 directory안에는 level의 resource들이 존재하게 됩니다. 이렇게 directory를 구분 함으로써 각 resource들의 위치를 쉽게 파악하면서 Infra의 change가 있을 때 다른 resource들이 영향을 받는 일이 줄어들게 됩니다.
이렇게 Datawarehouse의 대부분의 리소스들(Table은 Python DDL Client로 관리)을 코드로 관리함으로써 아주 효율적으로 관리할 수 있게 됐습니다.
지금까지 Sendbird Data Infra팀에서 어떻게 Datawarehouse Governance를 구축했는지에 대해서 설명해 드렸습니다. 저희가 다룬 부분을 다시 한번 살펴보면 아래와 같습니다.
- Project structure
- Security
- IAM
- Audit
- VPC
- Monitoring
- Performance
- Cost(Slot usage)
- Performance
- Table 구조
- Partitioning & Clustering
- Table Schema Management
- Resource Management
워낙 많은 부분을 다루다 보니 놓친 부분도 있을 것 같습니다. Sendbird는 언제든 기술에 대한 논의를 환영하고 있습니다. 더 궁금하신 부분이 있으시다면 편하게 댓글이나 혹은 이메일(infra.data@sendbird.com)로 연락해주세요! 또, 끊임없이 성장하고 있는 Sendbird의 Data Infrastructure를 함께 만들고 싶으신 분이 계시다면 꼭 지원 부탁드립니다! 긴 글 읽어 주셔서 감사합니다!
Sendbird 채용
Sendbird Careers










