
VM 기반 워크로드에서 서비스 투입 시간을 줄이기 위한 고군분투

소프트웨어 엔지니어링을 하다보면 머리속의 Best Practice는 따로 있지만 눈 앞의 현실과 타협해가며 진행해야하는 일들을 맞닥뜨리고는 합니다. 이번 글에선 그렇게 세련되진 않았지만 우리가 당면한 문제를 어떻게 정의하고 단계 단계를 밟아 처리하고 있는지 공유 드리려합니다.
센드버드에서는 다양한 서비스를 컨테이너 기반으로 EKS 환경에서 운영하고 있습니다. 하지만 여전히 가상 머신 기반으로 배포되는 서비스들이 남아있습니다. 이런 서비스들은 EC2를 기반으로 관련 AMI를 릴리즈 마다 빌드해서 관리되고 있습니다. 아무래도 컨테이너 단위가 아닌 VM 단위로 배포가 되다보니 이미지를 빌드하는데도 많은 자원이 소모되고, 배포 시 인스턴스가 생성되고 실제 서비스 트래픽에 투입되기까지 상당한 시간이 걸리는 문제가 있습니다. 가장 좋은 방법은 이런 문제가 없게 다른 서비스들처럼 컨테이너화 하여 EKS 기반으로 엔지니어링을 하는것이겠지만 해당 서비스는 변경에 다소 민감한 상태로 바로 EKS환경으로 급하게 전환하기는 쉽지 않은 상태 였습니다. 하지만 서비스 투입 시간이 지연되면 생기는 부작용들이 있었기에 이를 해결할 필요가 있었는데요. 이 포스팅은 이런 VM 기반의 워크로드들에 대한 서비스 투입 시간을 개선한 사례를 공유드리려합니다.
먼저 서비스 투입 시간을 줄이는게 왜 중요할까요?
트래픽에 보다 기민하게 대응하기 위함입니다. 갑작스런 트래픽에 보다 유연하게 대응할 수 있도록 보통 서비스들은 어느정도 가용 리소스에 여유를 두고 운영하게 됩니다. 요컨데 지금 트래픽을 처리하는데 드는 리소스가 7정도면 실제 운영하는 리소스는 10정도로를 투입하여 갑작스런 트래픽이 생길때 필요한 스케일링 시간을 확보합니다. 이때 스케일링하는 시간이 오래걸릴수록 우리는 보다 많은 여유를 가용 리소스에 투입해야할것 입니다. 보다 빠르게 스케일링을 할수 있으면 전반적인 리소스의 활용도가 높아지고 결과적으로 리소스의 낭비를 줄여 비용을 보다 아낄 수 있습니다.
그럼 기존에 서비스 투입에 걸리는 시간은 왜 오래 걸렸을까요?
해당 서비스는 VM을 기반으로하고 있어 배포가 될때 VM의 부팅에 상당한 시간을 소모합니다. 특히, 우리가 사용하는 Ubuntu 기반의 VM 이미지는 그간 충분히 튜닝되지 않아서 사용하지 않던 패키지가 많이 포함되어 있었고 그 크기가 상당했습니다.
워크로드의 설정을 부팅 이후 런타임에 동작하는 Ansible에 의존하고 있었습니다. Ansible에서는 외부로부터 필요한 정보를 수집하고 이를 가공, 설정을 만들어 내는데 많은 시간을 소모하고 있습니다.
스팟 인스턴스에 대한 로드밸런서의 헬스체크와 관련해서 AWS에는 버그가 하나 있습니다. 이로 인해 인스턴스 라이프 사이클을 활용하여 시간 지연을 임의로 두고 있었는데 이로 인해 시간이 더 오래걸리고 있었습니다.
로드밸런서의 헬스체커도 지나치게 보수적인 설정을 쓰고 있어 실제 서비스 투입 가능한 시간이 한참 지나서야 인 서비스로 투입됩니다.
이와 관련해서 인스턴스가 부팅되고 나서 서비스에 투입되기까지 소요되는 시간은 다음과 같습니다.

대략 4분의 시간이 걸립니다. 먼저 인스턴스가 생성된 후 실제 관련 설정 초기화가 시작되는 단계까지 가는데 상당한 시간이 소요되는걸 알 수 있습니다. 이 부분에 대해선 기반 OS별로 차이가 있을걸로 여겨져 관련 리서치를 먼저 진행했습니다.
OS별로 부팅 시간 비교해봅니다.
측정에는 다음과 같은 오픈소스를 활용했습니다.
https://www.daemonology.net/blog/2021-08-12-EC2-boot-time-benchmarking.html
센드버드에서 EC2 이미지는 ARM64를 주로 쓰지만 스팟 풀을 충분히 확보하기 위해서 x86_64 기반의 이미지도 같이 빌드하고 있습니다. 그런 이유로 양쪽 아키텍처에 대해서 모두 자료를 수집했습니다.
x86_64
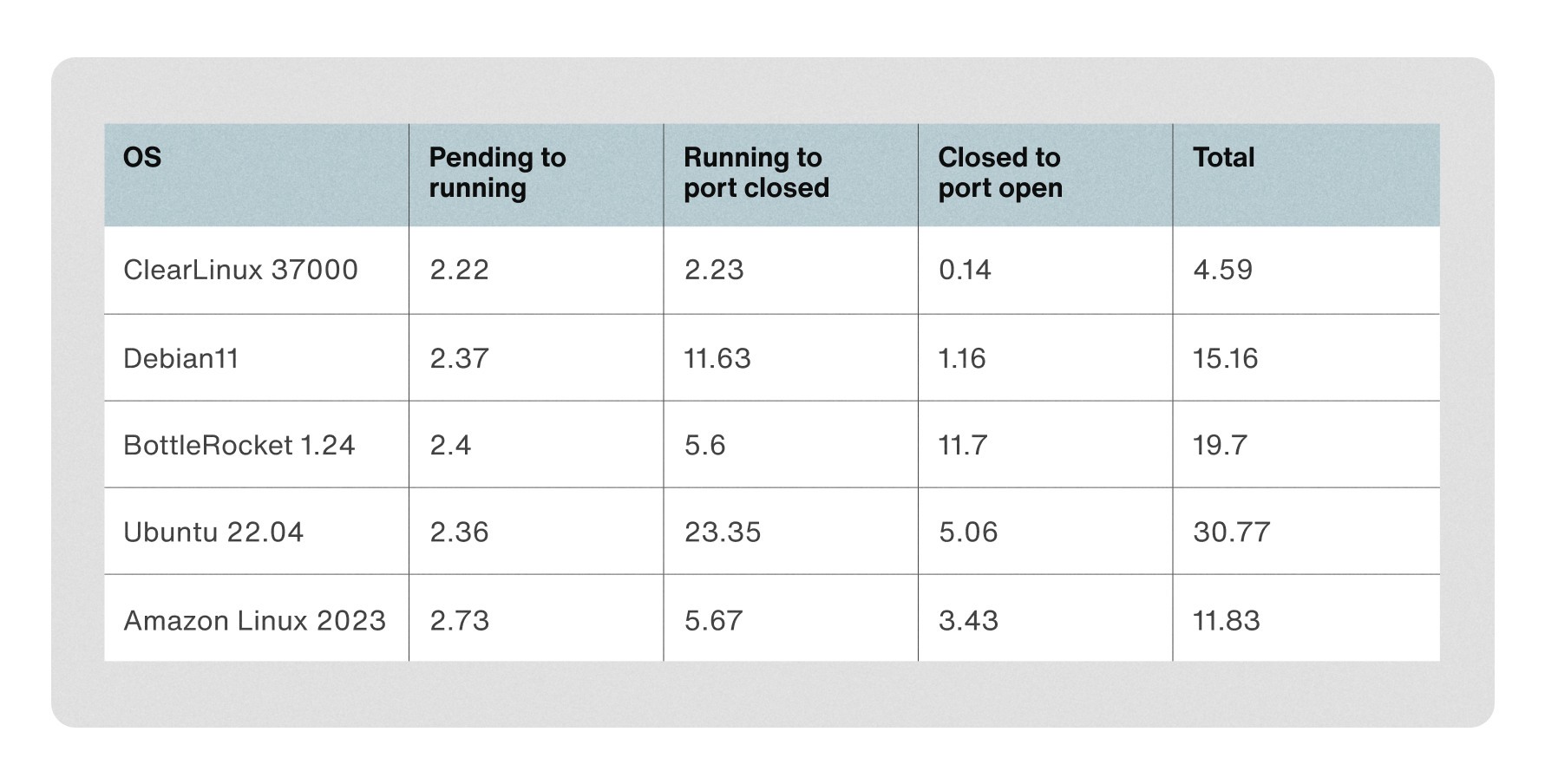
Intel의 Clear Linux가 압도적인 부팅속도를 보였습니다. 데비안도 우수한 결과를 보여줬습니다.
- arm64
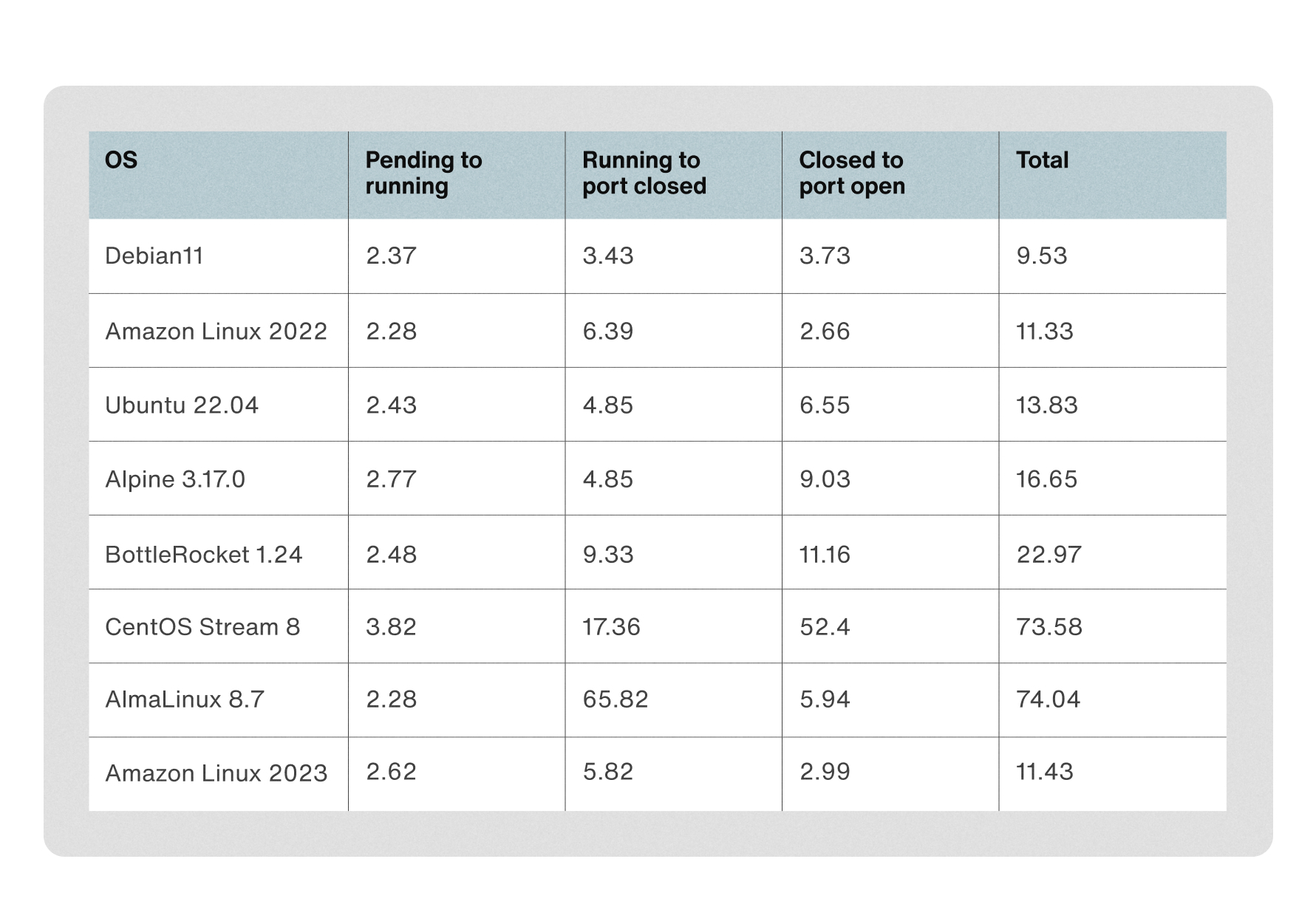
종합적으로 볼때 x86_64, Arm64 양쪽에서 가용하면서 충분히 빠른 Debian OS를 먼저 검토하게 되었습니다. 대신 기존 Ubuntu 환경과 맞춰 컨테이너 이미지의 베이스는 우분투를 썼습니다.
Containerization
그간 미뤄뒀던 컨테이너화의 개선 또한 진행했습니다. 로컬이나 CI 등의 개발환경과 프로덕션 리전간의 컨테이너 이미지나 설정에서의 갭이 존재했고, 이를 대부분 통합해낼 수 있었습니다. 설정에 대한 이야기는 아래에서 좀 더 자세히 다루도록 하겠습니다.
컨테이너 이미지의 크기도 부팅속도에 큰영향을 주었고, 이 시간을 줄이기 위한 고민도 필수적이었습니다. 그래서, 최대한 부팅시점에 적은 레이어를 가져올수 있도록 AMI를 빌드할때 변경이 잦지 않은 부분은 최대한 캐시할수 있도록 구성하였습니다. 또한, 컨테이너 이미지 사이즈를 줄이기 위해 빌드에만 사용되는 라이브러리나 패키지를 구분하고 지우는 과정이 필요했습니다.
Configuration Management 개선
기존에 Ansible을 통해 진행되는 설정 관리는 다음과 같았습니다. 기본적인 인프라와 관련 엔드포인트 들은 Terraform을 통해 관리되고 있고 Terraform에선 관련된 정보가 갱신될때마다 AWS S3 내 특정 버킷에 파일을 만듭니다. 새로운 인스턴스가 부팅되면 Ansible은 관련 버킷에서 필요로하는 파일을 받고 이를 기반으로 설정파일들을 생성하고 필요한 서비스들을 실행시켜줍니다. 이 과정을 그림으로 나타내면 아래와 같습니다.
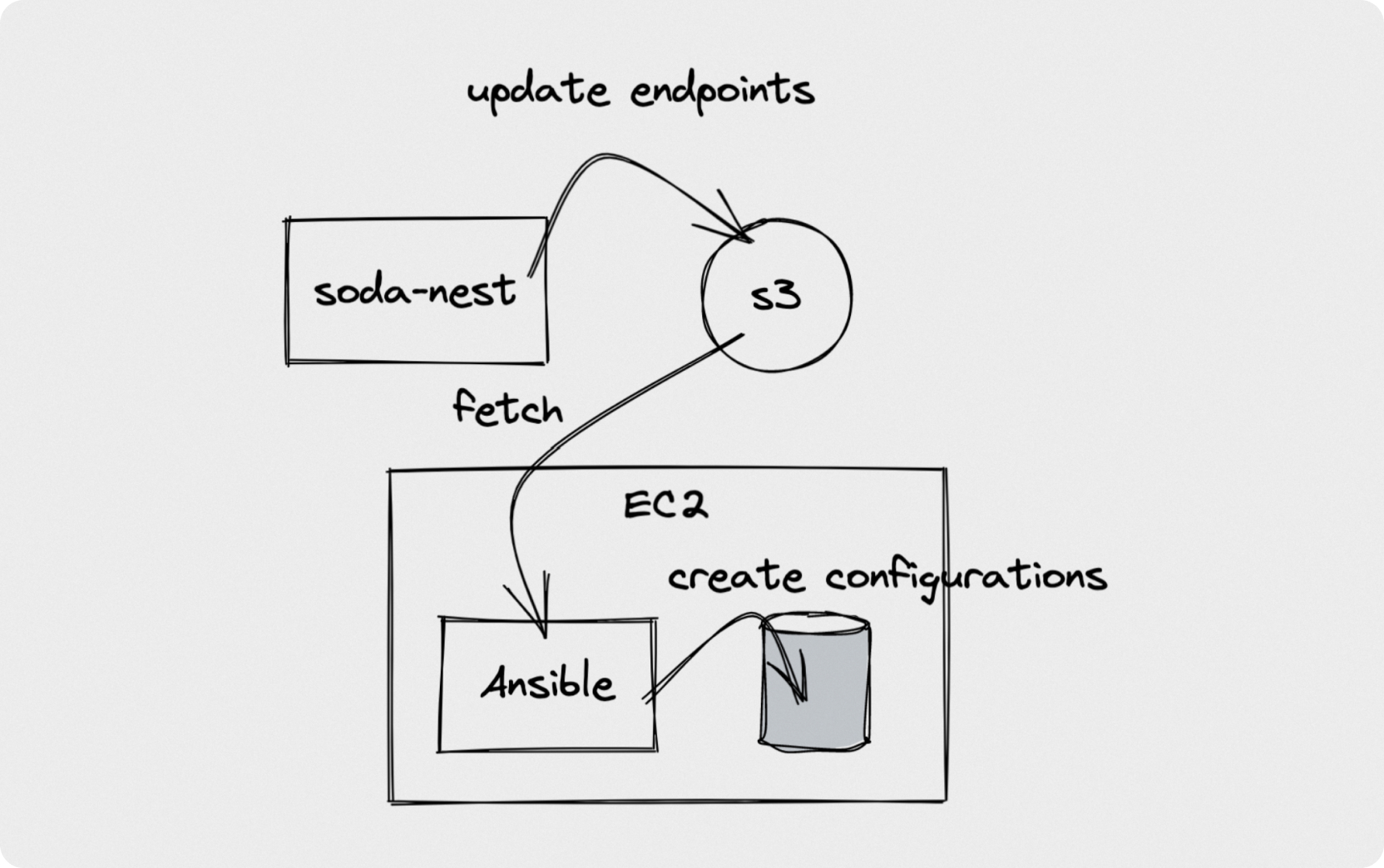
Ansible은 부팅 과정 외에도 다양한 경로에서 사용됩니다. 예를 들어 RabbitMQ를 교체해야하는 시나리오에서는 다음과 같이 동작하게 됩니다.
메인터넌스 작업을 위한 EC2 인스턴스 생성
관련 설정을 생성
ZK에 새로운 설정을 업데이트
워크로드 인스턴스에 에이전트에서 변경을 감지하고 필요한 Ansible Job을 실행
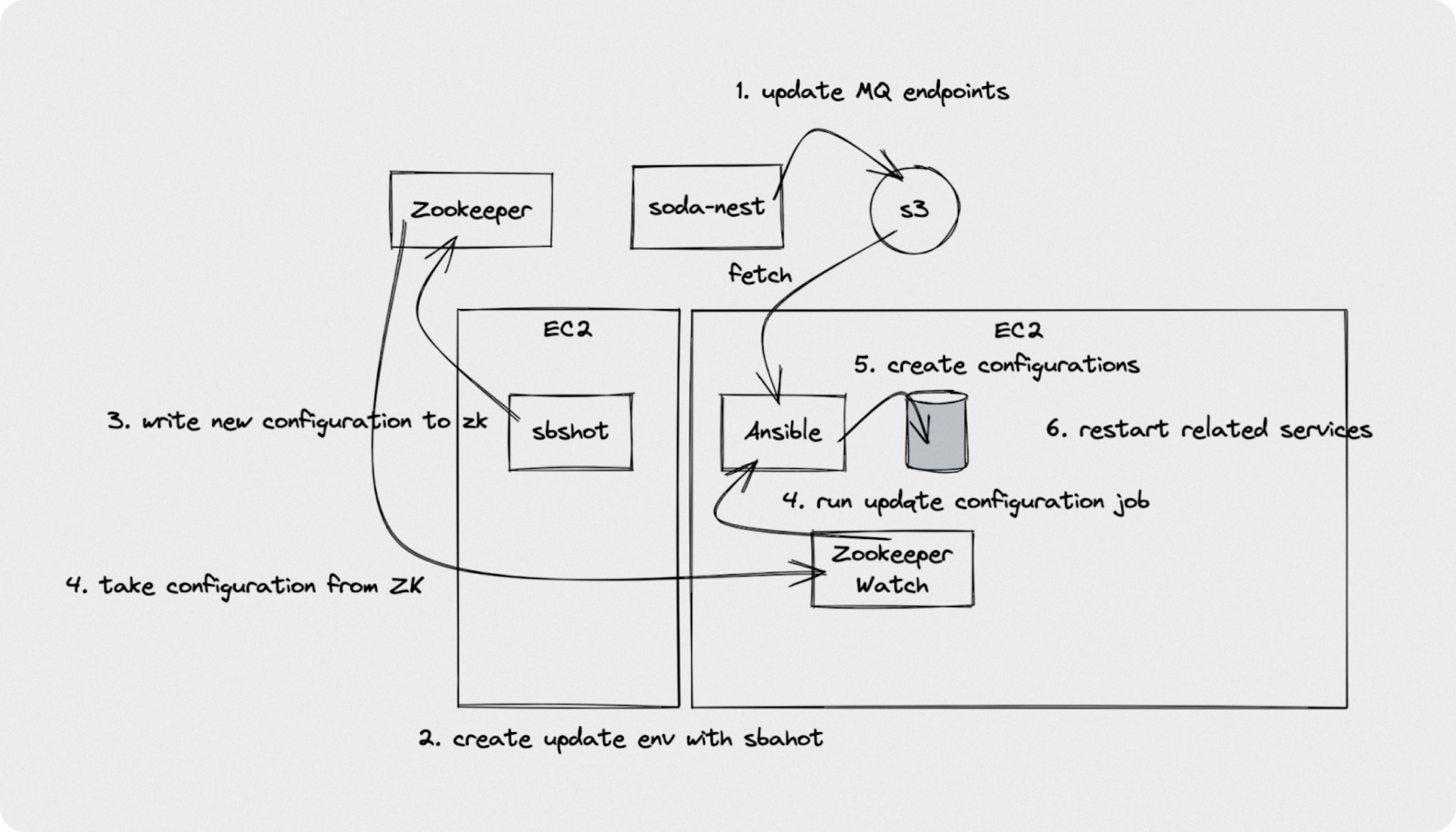
이 과정은 최대한 자동화가 되어 있었지만 많은 컴포넌트들이 엮여 있는관계로 유지보수하기가 까다로웠습니다.
이에 다음과 같은 목표로 새로 설정 관리 프레임워크를 구축하기로 했습니다.
설정 관리는 절차적인것 대신 선언적으로 관리
위의 MQ 교체와 같은 과정을 보다 간단하게 만들기
Terraform과 같은 외부 상태와는 의존성을 보다 느슨하게 만들기
ZK 외에 다른 저장소 옵션을 사용하기
ZK 대신 설정을 관리하는데는 Consul 등 여러 옵션이 있었지만 기 존재하는 EKS 환경을 재활용 하도록 결정했습니다. Consul 생태계의 consul-template과 비슷한도구는 Kubernetes에 존재하고 있지 않았으므로 비슷한 역할을 하는 Agent `Kubewatch`를 새로 만들기로 합니다.
왜 Consul을 쓰지 않았을까요?
현재 센드버드에서는 수백개 VPC에서 수백개의 배포 리전이 존재합니다. 가능하면 관리하는 컴포넌트 수를 줄이고 싶었고 이미 각 리전엔 EKS가 있었으므로 이를 재활용하고자 했습니다. 마침 AWS에서는 EKS의 컨트롤 플레인 리소스에 대해선 따로 과금하는 포인트가 없어 비용면에서도 이게 효율적이라고 판단했습니다. 또한 EKS를 재활용하면 상대적으로 Zookeeper나 Consul에 비해 많은 성숙한 도구들을 재활용할 여지가 있었습니다. 예를들어 설정을 관리하고자할땐 이에 대한 변경관리가 중요한데 ArgoCD와 같은 도구를 활용하여 GitOps 방식으로 이를 관리할 수 있습니다.
다만 Kubernete에는 consul-template와 같은, 설정을 인스턴스로 배포하는 에이전트가 따로 존재하지 않는데 이를 위해 Kubewatch라는 별도 에이전트를 개발했습니다. Kubewatch는 EKS내 ConfigMap과 Secret을 살피고 변동사항이 생겼을때 이를 가져와 현재 인스턴스에 반영, 그 후 필요한 액션을 실행하는 간단한 에이전트입니다.
이를 활용한 초기 설정 진행은 다음과 같습니다.
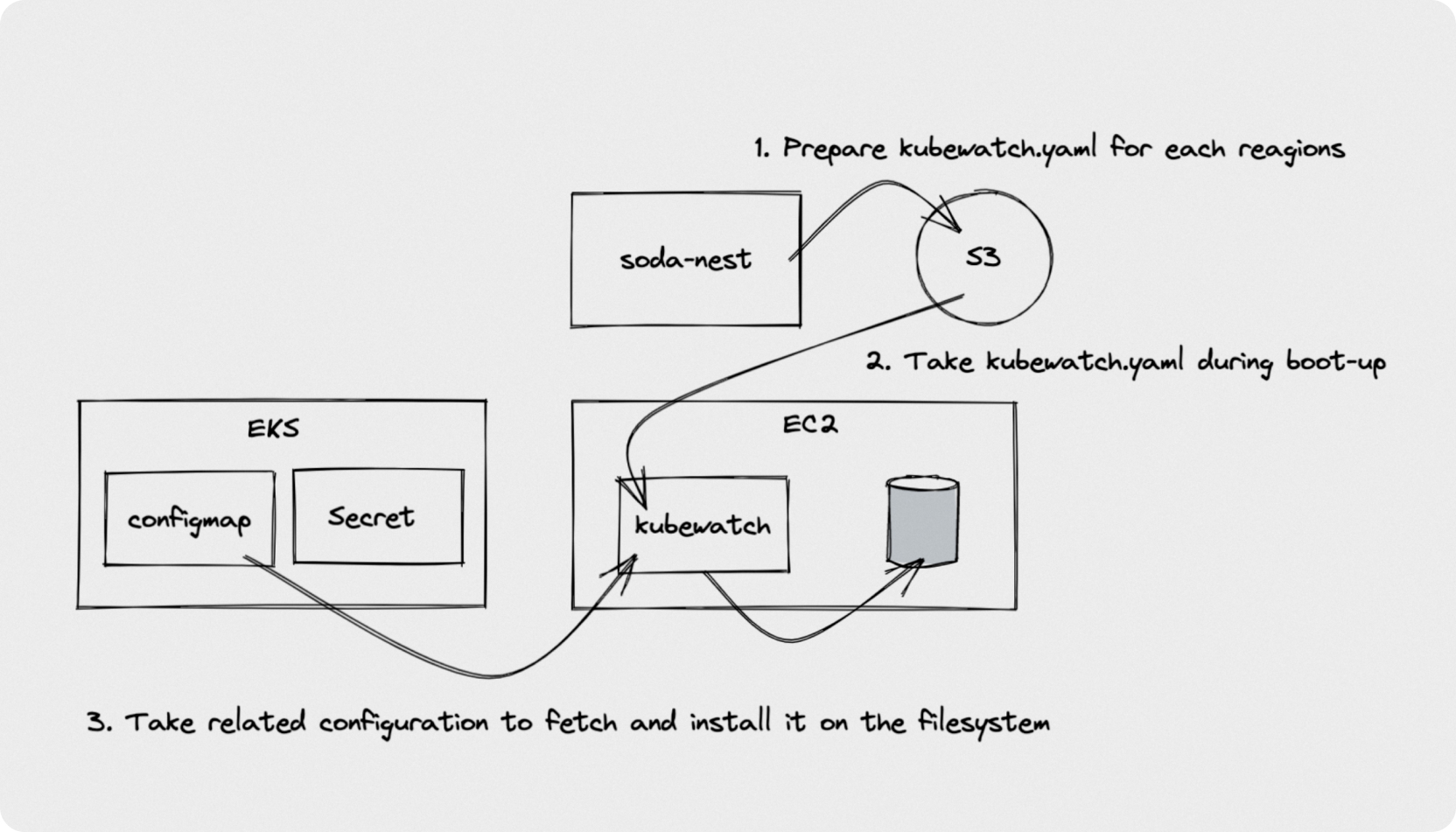
워크로드의 모든 설정은 Configmap과 Secret으로 관리됩니다. Secret의 경우 외부 Secret Store에 있는 값은 External Secret Operator를 통해 가져오게 됩니다. 인스턴스가 실행되면 Kubewatch가 즉각 이 값들을 가져와 정해진 위치에 두고 런타임에 결정되야하는 설정들을 생성하던가 서비스를 기동하는 등의 동작을 수행합니다.
MQ 교체와 같은 시나리오에서도 아래와 같이 진행됩니다.
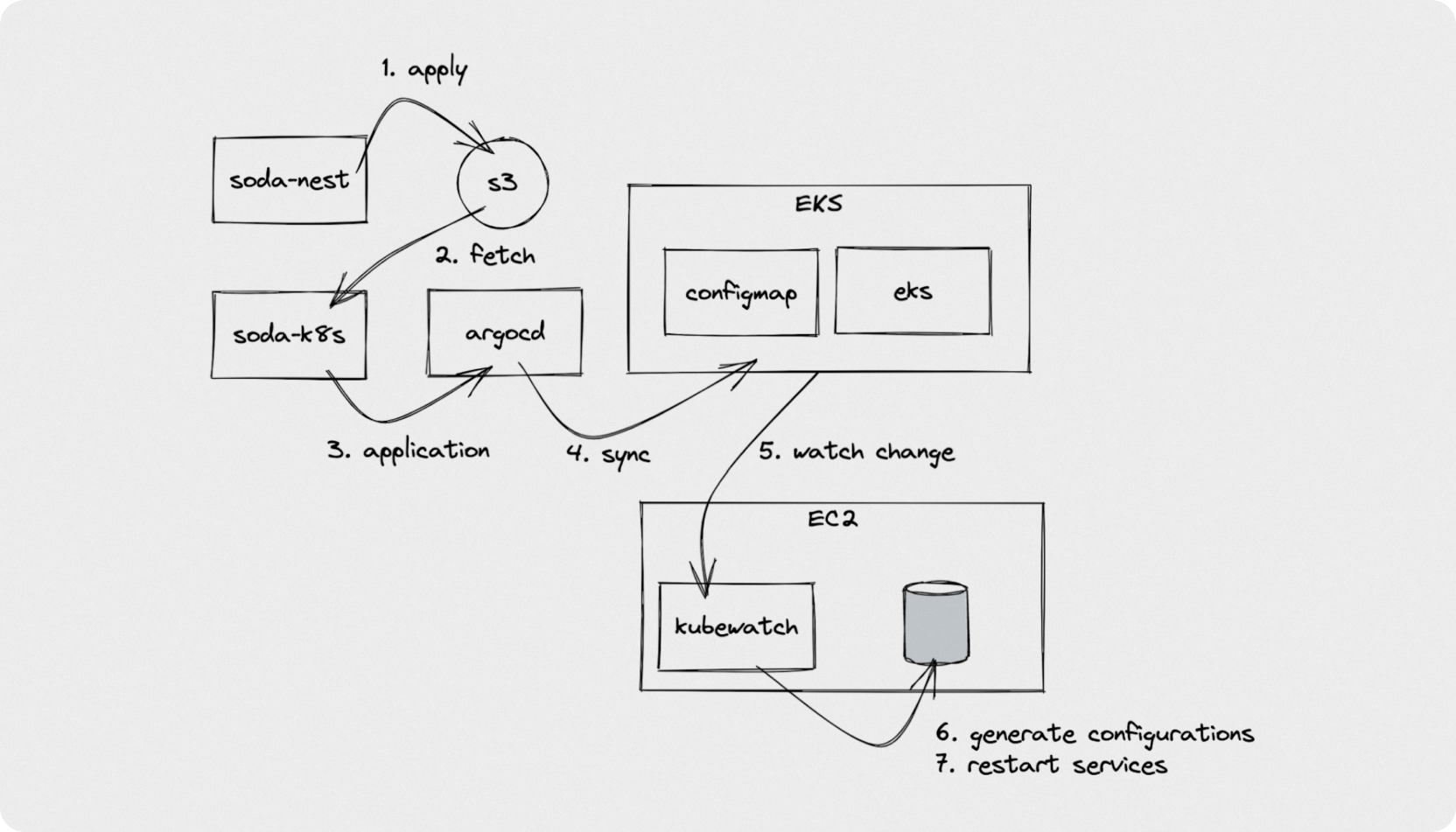
언뜻 여전히 복잡해보이지만 실제 작업은 새로운 MQ instance와 새로운 설정을 준비하는 과정으로 Github에 Pull Request를 두번 사전에 작업하고,
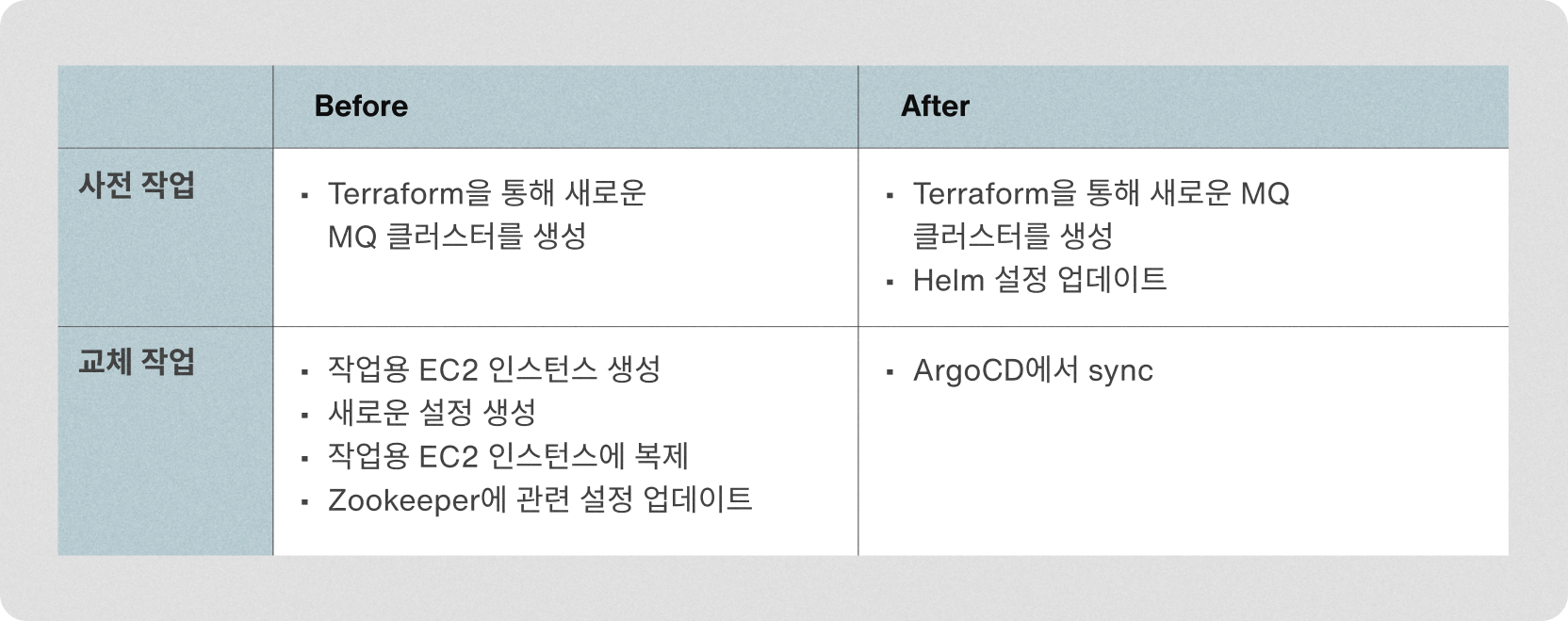
실제 교체시점엔 ArgoCD에서 sync버튼을 한번 눌러주는것만으로 교체가 완료되는 상태가 되었습니다. 표로 비교해보면 다음과 같습니다.
와중에 많은 시행착오가 있었습니다.
설정 미스
불명확한 초기 부팅 지연
배포 리전별로 이런저런 설정의 차이들이 있었는데 기존 설정과 똑같이 만들어내는지 체크하는 도구를 사전에 만들어서 활용했음에도 불구하고 몇차례 문제가 있었습니다.
초기 부팅 지연과 관련해서는 다양한 형태의 이슈가 있었습니다. 이 부분은 이전엔 눈에 띄지 않는 부분이었으나 설정 초기화 부분이 개선되면서 그 지연이 이전보다 두드러지게 보이게 된 경우 였습니다.
IMDS resolution 지연
이 부분은 처음 목격했을때 크게 당황했던 포인트입니다. cloud-init에서 네트워크 구간을 초기화하면서 IMDS 엔드포인트에 대한 리졸빙을 수행하는 구간이 있었는데, 해당 구간에서 무려 50초 정도의 지연을 보였습니다. 관련해선 resolvconf 패키지를 통해 if-{up,down} 및 DHCP 이벤트가 발생시 바로 resolver configuration을 만들도록 하여 해결이 되었습니다.
I/O 포화
초기 시점에 관련 프로세스들이 그대로 멈춰있는 현상이 보였습니다. I/O로 인한 지연을 의심했지만 이에 대해선 일반적인 iostat으로는 바로 판단하기 어려운점이 있었습니다. 이 부분은 PSI, Pressure Stall Information을 활용하여 가시화를 하고 관련 I/O포화로 인한 지연인걸 보다 명확히 할 수 있었습니다. https://docs.kernel.org/accounting/psi.html
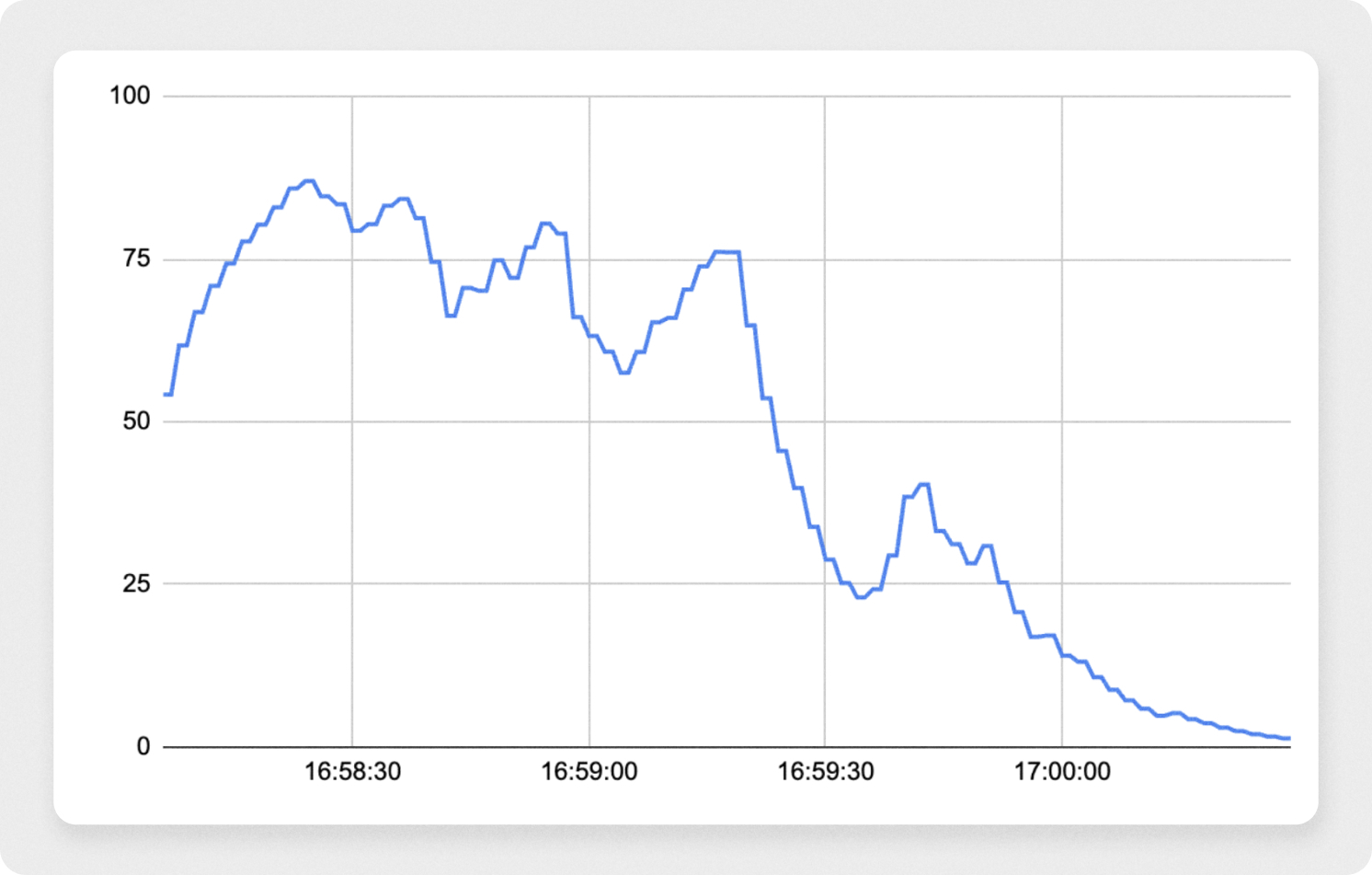
AMI snapshot 크기
초기 부팅 시점 지연은 AMI의 Snapshot 크기와도 관계가 있었습니다. AMI의 snapshot으로 부터 인스턴스가 생성될땐 s3에 존재하는 snapshot을 가져오는 구간이 존재합니다. 기존에는 여기에 할당된 볼륨으로 약 15GB로 사용하였는데 관련 볼륨의 사이즈를 절반정도로 줄였을때 상당한 시간 차이가 생기는걸 확인했습니다.
부팅 시간에 대한 모니터링
이번 프로젝트를 통해 부팅시간이 줄어들더라도 여러 변화에 의해 우리가 원하고자하는 부팅속도와의 괴리가 생긴다면 무용지물이 될 수 있습니다. 따라서, 가시성을 높이고 빠른 부팅속도를 유지하기 위해 부팅시간에 대해 메트릭을 추가하여 대시보드와 Alert을 통해 이를 모니터링 할 수 있도록 하였습니다.
그외 Lifecycle hook과 로드밸런서 헬스체커와 관련된 지연
AWS의 Autoscaling Group에는 한가지 버그가 있습니다. Purchase Option이 중간에 변경되는 경우 연결된 LoadBalancer의 Heatlcheck를 무시하고 바로 서비스로 투입되버립니다. 이를 방지하기 위해 센드버드에서는 Instance Life Cycle hook에 지연시간을 고정적으로 두고 이를 방지하고 있었습니다. 고정된 시간을 대기하고 있어 낭비가 있었는데 관련해서 서비스 트래픽을 받을 수 있는 준비가 되었다는 판단이 내려졌을때 lifecyecle hook completion을 통해 더 기다리지 않도록 했습니다. Lifecycle hook completion을 하더라도 실제 트래픽을 받는데 시간이 또 어느정도 걸렸는데요. 이 부분은 직접 Load Balancer로 인스턴스를 등록하면 해결 할수 있지만 과한 조치라는 생각이들어 AWS의 제어를 기다리는걸로 했습니다. 그외 그간 너무 방어적으로 동작하던 로드밸런스의 헬스체킹을 보다 완화하면서 마무리를 지었습니다.
결과적으로
위와 같은 다양한 엔지니어링을 결과로 부팅 후 서비스 온타임까지 시간을 기존의 4분에서 40초 수준까지로 줄일 수 있었고 가용 리소스 수준을 기존에 50~60%에서 70%까지 올려 전반적인 자원 활용도를 크게 개선할 수 있었습니다. 또한, 기존보다 낮은 수준의 가용 리소스만으로도 빠른 Scale out을 통해 Traffic surge에 효과적으로 대응하는 안정적인 서비스를 만들 수 있었습니다.
프로젝트를 시작할때 가장 주된 목표는 서비스 투입 속도를 개선하는것이었지만 엔지니어링적인 욕심으로 많은 곁가지들이 붙게되었습니다. 작업을 진행하면서도 그냥 바로 EKS로 전환해도 되지 않았을까라는 생각도 들었지만 결과적으로 보다 안전하게 차차 개선하는 방식을 선택했던게 장기적으로는 더 나은 선택이었던것 같습니다.
이번 프로젝트로 당초 목표했던 서비스 부팅 속도부터 그간 많은 부채가 있던건 설정 관리와 관련된 많은 잡무들을 제거하거나 개선할 수 있었습니다. 또한 앞으로도 해당 아키텍처를 개선해나가는데 필요한 엔지니어링 리소스들을 얻을 수 있었습니다.









