
SB-OSC: 센드버드 온라인 스키마 변경


Introduction
온라인 스키마 변경은 MySQL 데이터베이스를 사용하는 서비스를 개발하고 운영하는 데 있어서 필수적인 과정입니다. 데이터 구조의 지속적인 최적화, 새로운 기능의 추가, 성능 개선, 또는 데이터 보안 강화를 위해 기존 테이블 구조를 변경할 필요가 자주 발생합니다. 그러나 이러한 변경을 오프라인으로 수행하게 되면 서비스 중단이 불가피해지며, 이는 사용자 경험 저하 및 비즈니스에 심각한 영향을 미칠 수 있습니다. 따라서 다운타임 없이 데이터베이스 스키마를 변경할 수 있는 온라인 스키마 변경 방식이 매우 중요합니다.
기존의 온라인 스키마 변경 툴들, 특히 gh-ost, fb-osc, pt-osc는 각각 싱글 프로세스 툴들로 자신들의 진행 상황을 저장하지 않습니다. 스키마 변경은 다양한 원인들(ex 프로세스 오류, 테이블 락 경합, 부하로 인한 OS 킬)로 인해 중단되거나 종료될 수 있으며, 이 경우 스키마 변경을 재개 할 수 없습니다. 중단된 작업을 처음부터 재시작하기 위해선 잔여 테이블을 정리해야 하며, pt-osc와 fb-osc의 경우 남아 있는 트리거도 제거하야 합니다.
특히 대규모 테이블에서 이러한 문제는 더욱 심각합니다. 수백 기가바이트에서 수 테라바이트에 이르는 데이터를 갖는 테이블에 대한 온라인 스키마 변경 작업이 수 주 ~ 수 개월까지 늘어나게 되면, 비즈니스의 빠른 변화와 성장에 데이터베이스가 대응하지 못할 수 있으며 큰 기술 부채로 이어질 수 있습니다.
이러한 배경 하에, 저희 팀은 대용량 테이블 스키마 변경의 경험을 바탕으로 멀티스레딩 기반의 새로운 MySQL 온라인 스키마 변경 툴, SB-OSC를 개발하였습니다. SB-OSC는 멀티스레딩을 통해 기존 툴들의 시간적 한계를 극복하며, 대규모 테이블에서도 스키마 변경 작업을 수 일 이내로 대폭 단축시킵니다. 또한, SB-OSC는 작업이 어떻게 실패하더라도 binlog만 살아있다면 끊어진 지점에서 완벽하게 작업을 재개할 수 있는 강력한 기능을 제공합니다. 이는 기존에 수 개월이 소요되던 작업 시간을 혁신적으로 개선하며, 기존에 거의 불가능에 가까웠던 대규모 OLTP 테이블에서의 스키마 변경을 가능하게 하였습니다.
본 블로그에서는 SB-OSC의 설계 철학과 구현 방식을 자세히 소개하며, 대규모 테이블에서의 스키마 변경이 갖는 도전과 그 해결책에 대해 심도 있는 이해를 제공하고자 합니다.
Methodology
SB-OSC의 설계는 두 가지 핵심 철학에 근거합니다. 첫째, 작업이 중단되거나 재시작될 때 중단 시점에서 재개할 수 있는 능력을 갖추는 것입니다. 이를 위해, SB-OSC는 작업을 명확히 정의된 단계별로 나누고, 각 단계의 진행 상황을 데이터베이스에 기록합니다. 또한, 각 단계의 진행 정도를 복구할 수 있도록 필요한 최소한의 데이터를 데이터베이스에 저장합니다. 이렇게 함으로써, 작업이 중단되었을 때 중단된 단계에서부터 재개할 수 있습니다. 이는 작업의 중단 및 재시작에 따른 복잡성과 위험을 대폭 줄여줍니다.
둘째, SB-OSC는 멀티스레딩을 통한 성능 최적화를 추구합니다. 이를 위해, SB-OSC는 원본 데이터를 복사하는 ‘Bulk import’ 단계와 ‘DML 이벤트 반영’ 단계를 분리하였으며, DML 이벤트를 기존의 구문 반영 방식이 아닌, 원본 데이터를 primary key(이하 PK)로 조회하여 복사하는 방식으로 처리합니다. 이러한 설계는 복잡한 DML 이벤트의 순서에 신경 쓰지 않아도 되며, 원본 테이블의 최종 상태만 정확하게 맞추면 되기 때문에 멀티스레딩을 적용하는 데 큰 이점을 제공합니다.
특히, binlog를 파싱하는 단계에서도 분당 수 기가바이트의 binlog가 생성되는 상황을 극복하기 위해 멀티스레딩을 지원할 수 있도록 구현하였습니다. SB-OSC는 binlog 파일 단위로 멀티스레딩을 적용하여, 일반적인 상황에서는 단일 스레드로 운영되지만, 필요에 따라 여러 binlog 파일을 동시에 처리할 수 있습니다. 대량의 DML 이벤트가 발생하여 단일 스레드로 binlog 파싱 속도가 쌓이는 속도를 따라가지 못하는 상황에서 SB-OSC는 이를 통해 초당 수천 개의 DML 이벤트가 발생하는 테이블에서도 실시간에 가까운 binlog 파싱을 가능하게 합니다.
이러한 설계 철학과 기능은 SB-OSC가 대규모 데이터베이스 환경에서 더욱 강력하고 유연하게 동작할 수 있게 해줍니다. 이제 각 단계별로 위와 같은 철학을 어떻게 구현해 내었는지를 자세히 살펴보겠습니다.
0. Initialization
Initialization 단계는 SB-OSC의 동작에 필요한 여러 테이블들과 Redis 키를 정의하는 단계로, 작업이 중단되었을 때나 데이터에 문제가 발생했을 때 이를 자체적으로 해결할 수 있는 기반을 마련합니다. SB-OSC는 DB와 Redis 두 개의 저장소를 사용합니다. DB는 스키마 변경을 진행하는 DB에 별도의 논리 DB를 만들어 복구를 위한 다양한 데이터들을 저장하고, Redis는 SB-OSC의 여러 프로세스들이 공통적으로 빠르게 접근할 수 있는 정보들을 저장하게 됩니다. 데이터베이스 테이블들은 작업 재개를 위해 유실되면 안되는 데이터들을 저장하고, Redis에는 SB-OSC의 여러 컴포넌트들이 공통적으로 사용하며 자주 접근해야 하는 데이터들을 저장합니다.
1. Binlog 파싱
Binlog 파싱 단계는 binlog를 파싱하여 DML이 발생한 이벤트들을 찾아내는 단계로, 두 가지 주요 특징을 갖습니다.
하나는 DML 이벤트를 수집해서 INSERT, UPDATE, DELETE 세 개의 별도의 테이블로 저장한다는 것입니다. 여기서 DML 이벤트의 구체적인 내용은 저장하지 않고, INSERT, UPDATE, DELETE가 발생한 PK 값만 발생한 timestamp와 함께 각각 별도의 테이블에 저장합니다.
이 테이블 저장 방식의 선택에는 여러 이유가 있습니다.
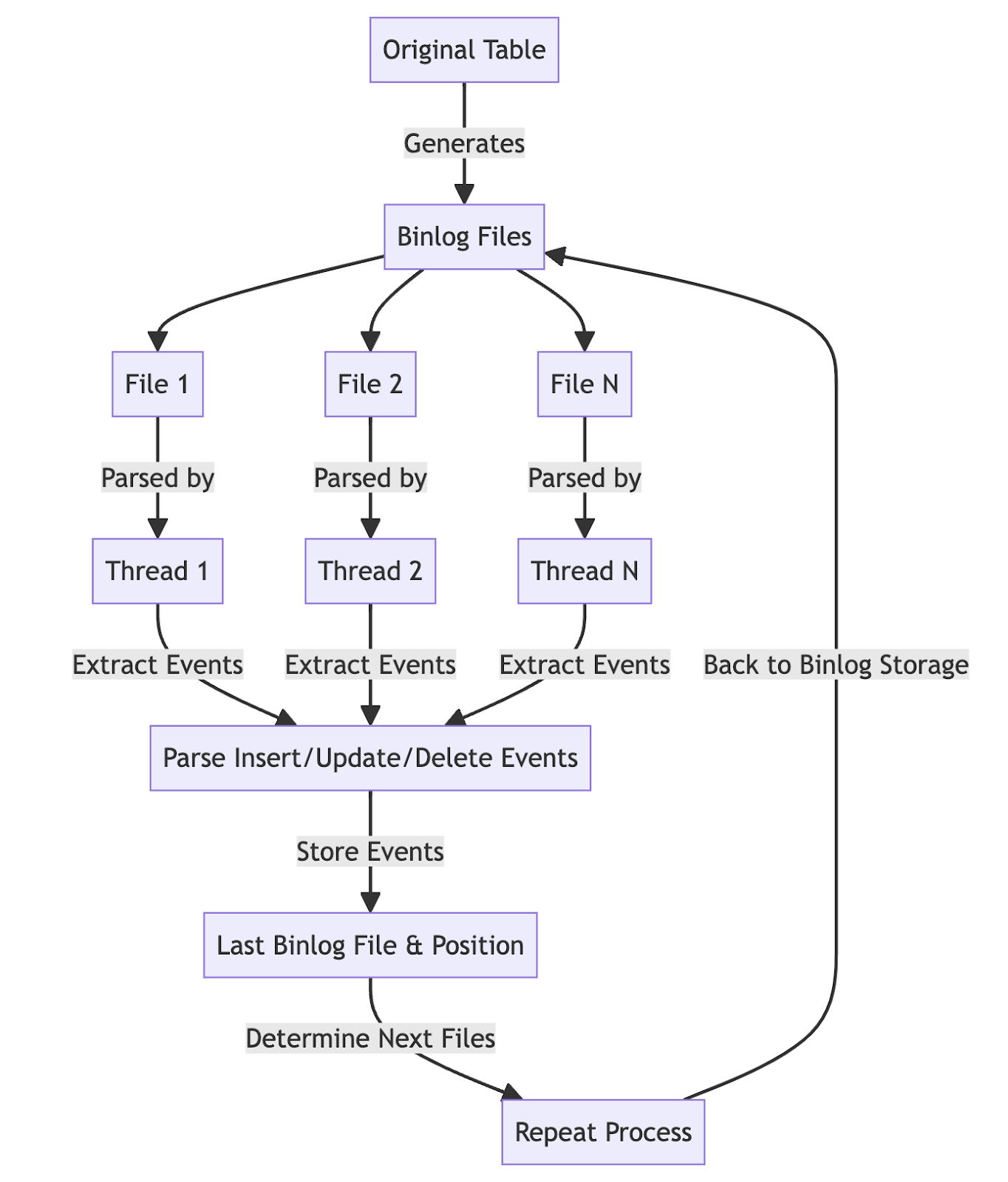
먼저, 현 시점까지의 이벤트를 저장함으로서 작업을 중단된 시점에서 재개할 수 있도록 합니다. Binlog에서 INSERT, UPDATE, DELETE 이벤트를 파싱 할 때 일정 주기, 또는 특정 개수 만큼의 이벤트를 찾을 때마다 이를 저장하게 되는데 먼저 INSERT, UPDATE, DELETE 이벤트 저장을 한 뒤에 현재 binlog 파일과 포지션, 그리고 마지막 timestamp를 테이블에 기록하게 됩니다. Binlog 파싱 프로세스가 시작을 할 때 해당 테이블의 마지막 레코드를 참조하여 그 위치에서 재개하기 때문에 이벤트를 각 테이블에 기록하고 포지션을 기록하는 것은 Binlog에서 파싱된 모든 이벤트가 DB에 저장되는 것을 보장하고, 또 작업을 재개할 수 있는 장치가 됩니다.
두 번째로, DB에 저장을 할 때 INSERT INTO UPDATE ON DUPLICATE KEY 를 수행하기 때문에 동일 PK에 대한 중복 UPDATE 를 제거하는 역할을 합니다. 구문을 반영하는 것이 아니라 PK에 해당하는 레코드를 원본에서 다시 복사해오기 때문에, 동일 PK에 대한 중복된 업데이트 발생했을 경우 최종적으로 한 번만 업데이트를 수행해주면 되기 때문에 이를 통해 원본 테이블에 발생한 업데이트를 효과적으로 따라갈 수 있습니다.
마지막으로, 이벤트가 발생한 PK들을 여러 번 재활용할 수 있게 해줍니다. 이는 특히 DML 이벤트를 반영하는 과정에서 여러 번의 정합성 검증이 이루어 질 때 유용하게 활용됩니다. DB에 이벤트를 저장함으로써 해당 PK에 대한 정합성 검증을 반복적으로 수행할 수 있게 해줍니다.
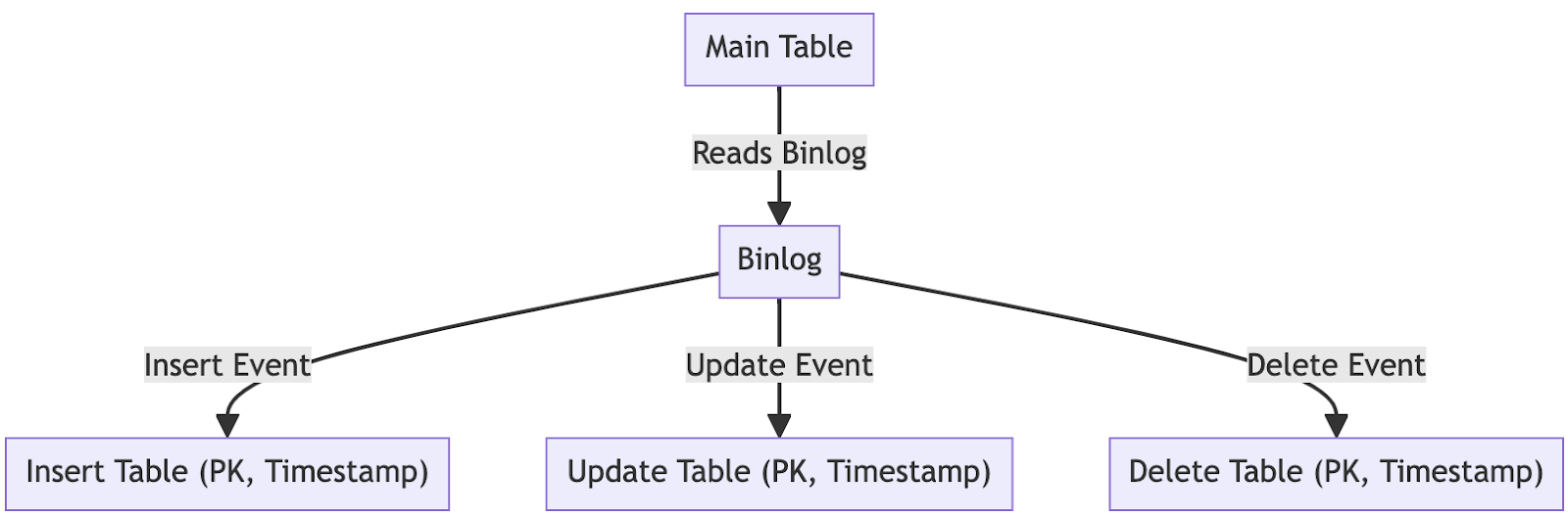
두 번째 특징은, binlog파일을 동시에 여러 개 처리하는 멀티스레딩을 적용했다는 것입니다. 일반적인 상황에서는 단일 스레드로 동작을 하지만, 원본 테이블에서 DML이 대량 발생하는 경우 단일 스레드로는 계속 원본 테이블과의 격차가 벌어지는 문제가 발생했습니다.
SB-OSC에서는 이 문제를 binlog를 파일 순서대로 몇 개씩 묶어서 동시에 처리하고 발견한 이벤트 전체를 한 번에 처리함으로써 해결할 수 있었습니다. 마지막으로 읽은 binlog파일 이후에 2개 이상의 파일이 추가되었다면 SB-OSC는 이 파일들을 최대 4개까지 멀티스레딩으로 각각 처리를 한 뒤에 동일한 PK에 대한 중복 제거를 한 뒤 이들 전체를 DB에 저장하고, 가장 최근에 생성된 binlog파일과 마지막으로 읽은 포지션을 DB에 기록합니다. 이를 통해 초당 수천개의 DML이 발생하는 테이블에서도 실시간에 가깝게 binlog를 파싱할 수 있었습니다.
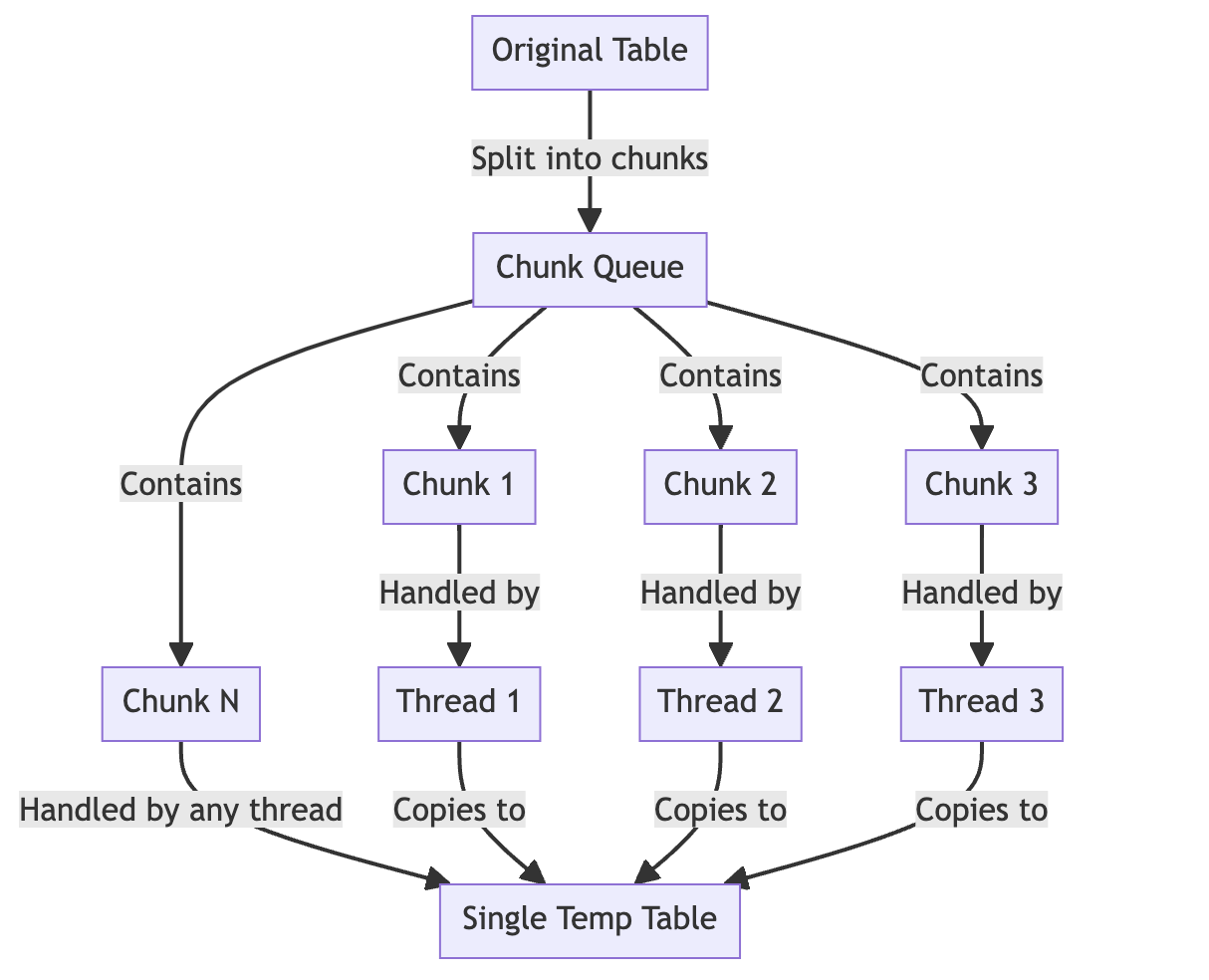
2. Bulk Import
Bulk import 단계는 원본 테이블을 새 테이블로 복사하는 단계로 테이블을 PK값을 기준으로 여러 개의 chunk로 쪼갠 뒤에 여러개의 chunk를 멀티스레딩으로 동시에 복사하는 단계입니다. 이는 SB-OSC의 멀티스레딩을 구현하는데 있어 핵심적인 단계입니다.
각각의 chunk를 하나의 스레드가 처리하고 각 스레드는 chunk의 range안에서 작은 batch단위로 INSERT INTO SELECT query를 수행합니다. Binlog 파싱 이후에 Insert 되는 PK들은 모두 별도의 테이블에 저장이 되기 때문에 이 때 복사하는 PK의 최대값은 binlog 파싱을 시작한 직후의 최대값으로 고정해두면, 이후에 쌓이는 레코드들은 모두 DML 이벤트 반영 단계해서 처리할 수 있게 됩니다.
현재 존재하는 온라인 스키마 변경 툴들은 테이블을 복사하면서 트리거나, binlog를 이용해 새 테이블에서 발생하고 있는 DML 이벤트를 실시간으로 반영해 주게 됩니다. 이 경우, 프로세스가 간단해지긴 하지만 대량의 DML이 발생하는 상황에서는 전체적인 속도를 저해하게 됩니다. Insert가 발생을 하면서 동일한 PK구간에 DML이 발생하기 때문에 서로가 락을 잡아 latency가 늘어나게 되고, 또 스키마 변경이 오랫동안 진행되게 되면, 초기에 복사가 된 레코드들에 대해서는 업데이트가 중복해서 여러번 발생하기 때문에 시간이 길어질수록 점점 더 누적된 부하가 높아지게 됩니다.
SB-OSC에서는 이 문제를 Bulk import와 DML 이벤트 반영을 분리함으로써 해결할 수 있었습니다. Bulk import 단계에서는 현재까지 저장된 PK들을 DML에 대한 고려 없이 복사만 하면 되기 때문에 멀티스레딩을 적용하여 빠른 속도로 대량의 레코드를 복사할 수 있었고, DML 이벤트 단계에서는 bulk import를 하는 과정 동안 발생한 중복된 PK를 모두 제거하여 효율적으로 DML 이벤트를 반영할 수 있었습니다.
3. DML 이벤트 반영
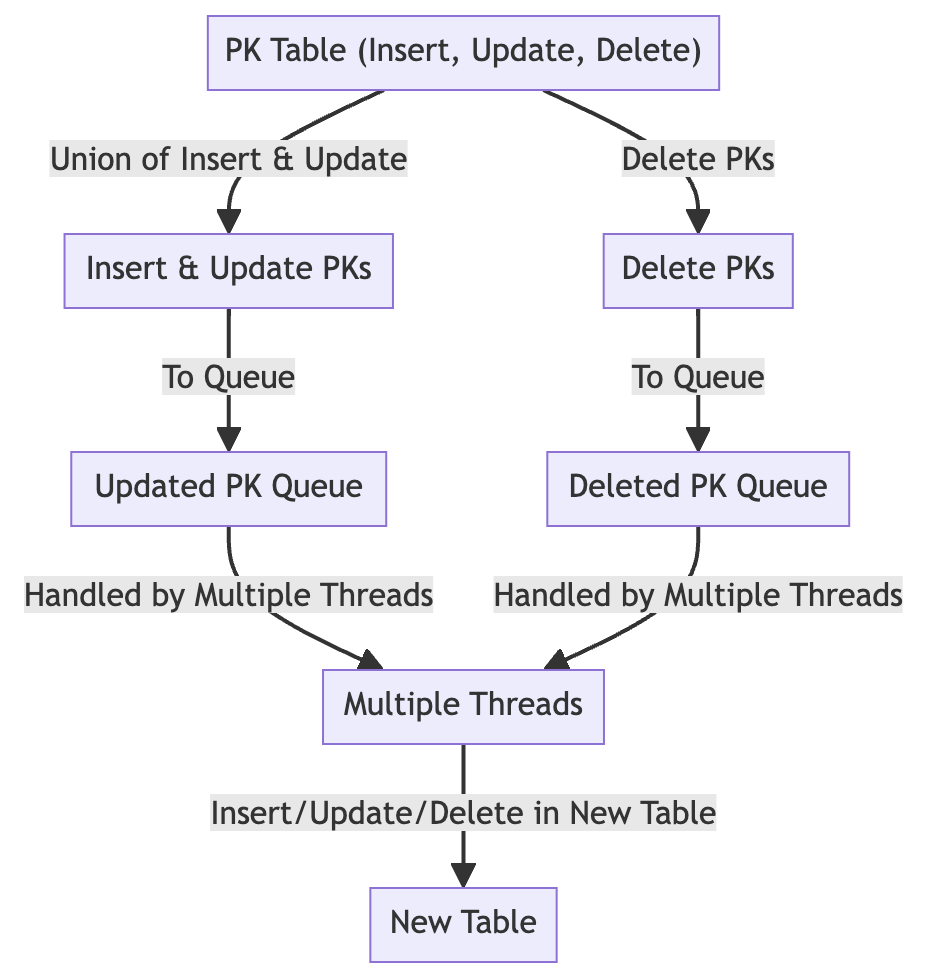
Bulk import가 끝나면, binlog parsing을 통해 저장된 DML 이벤트 들을 반영해줍니다. INSERT, UPDATE, DELETE가 발생한 PK를 저장한 테이블에서 시간 순서대로 이벤트를 읽어서 반영을 해줍니다. 위에서 설명한대로 실행된 구문을 반영하는 것이 아니라 해당 PK 값을 갖는 원본 테이블의 데이터를 그대로 다시 복사하기 때문에, 순서의 제약을 받지 않아 멀티스레딩 적용이 가능합니다.
추가적으로, 테이블에 저장할 때 중복된 PK의 업데이트를 INSERT INTO UPDATE ON DUPLICATE KEY로 최적화 하는 것에 더해, INSERT와 UPDATE가 발생한 PK의 합집합과 DELETE가 발생한 PK와의 차집합을 계산하는 방법으로 추가적인 최적화를 진행합니다. INSERT와 UPDATE는 INSERT INTO UPDATE ON DUPLICATE KEY를 사용하는 경우 동일한 query로 처리할 수 있기 때문에 합집합을 하고, DELETE가 발생한 PK는 DELETE가 INSERT나 UPDATE보다 후행되어 처리됐다면 다시 반영될 필요가 없기 때문에, 차집합을 계산합니다. 세부적인 이벤트 순서는 중요하지 않지만 이와 같은 추가적인 최적화를 위해 구간별로 시간 순으로 끊어 DML 이벤트를 반영해줍니다.
4. 테이블 교체
위의 과정이 모두 끝난 뒤에 더 이상 반영해줄 DML 이벤트가 없다면 새로 만든 새 테이블과 원본 테이블의 이름을 서로 교체합니다. 테이블 교체는 원본 테이블의 이름을 임시로 변경하여 트래픽을 차단하고, 이름을 바꾸는 순단에 들어온 DML 이벤트를 비동기로 새 테이블에 반영해준 뒤에 새 테이블의 이름을 기존 원본 테이블의 이름으로 바꾸는 과정으로 진행됩니다.
테이블 교체가 이루어지는 동안에도, binlog 파싱은 멈추지 않고 계속 진행이 되고, 테이블 교체하는 과정에서 DML 이벤트 반영이 이루어지지 않아 실패하게 되는 경우에는 임시로 이름을 바꾼 원본 테이블의 이름을 다시 원복하기 때문에, 정상적인 서비스 운영이 가능합니다.
만약 원본 테이블의 이름을 임시로 변경한 상태에서 프로세스가 재시작되게 된다면, information_schema.TABLES에서 원본 테이블과 동일한 이름의 테이블이 있는지를 최우선적으로 조회하여 없다면 임시로 변경한 원본 테이블의 이름을 원복하여 서비스를 정상화 시킨 뒤에 다시 테이블 교체를 시도합니다.
Sustainability
일반적으로 스키마 변경 작업에서 속도를 향상시키기 위해 멀티스레딩을 사용하게 되면 데이터 정합성을 보장하기 어려워질 수 있습니다. SB-OSC는 실제 운영 환경에서 발생할 수 있는 duplicate key, deadlock, connection error, timeout과 같은 다양한 문제들을 자체적으로 해결하고 정합성을 보장하기 위해, 여러 안전장치와 데이터 정합성 검증 로직을 구현하고 있습니다.
1. Binlog 파싱
이후 단계들의 정합성 검증 로직들에서 수 차례 DML 이벤트 들이 반영되었는지를 체크하기 때문에, binlog 파싱 부분에서는 DML 이벤트가 발생한 PK값들을 놓치지 않고 찾아서 DB에 기록해두는 것이 가장 중요합니다. 이를 보장하기 위해, binlog 파싱을 할 때 현재 읽고 있는 파일들이 모두 파싱이 완료가 된 뒤에 DB에 이벤트를 기록을 하고, 모든 이벤트가 성공적으로 기록된다면 현재까지 읽은 마지막 파일과 포지션 DB에 기록합니다. 이벤트 파싱 프로세스가 시작할 때, DB에서 이전에 읽은 파일의 위치를 찾아서 해당 위치부터 재개하기 때문에, 만약 이벤트를 저장하는 과정에서 오류가 발생한다면, 마지막에 성공적으로 저장한 위치에서 다시 재개하여 놓치는 이벤트 없이 모두 DB에 저장이 되는 것을 보장할 수 있습니다. 추가로 현재 존재하는 모든 binlog를 전부 파싱했는지를 체크하기 위해 파일의 끝에 다다른 시간을 Redis에 계속해서 업데이트 하여, 테이블 교체 단계에서 활용하게 됩니다.
2. Bulk Import
Bulk import 단계에서 사용되는 chunk들은 세 가지 방식으로 관리됩니다: Redis Set에는 chunk들의 식별자가 저장되며, Redis List를 사용한 Chunk Stack에서는 LIFO 방식으로 chunk들이 관리되고, 마지막으로 각 chunk의 상세 정보는 데이터베이스 테이블에 저장됩니다.
INSERT query를 수행하는 스레드는 Chunk Stack에서 chunk를 꺼내 이용합니다. Chunk가 선택되면, 해당 chunk의 상태는 각 chunk별 Redis Hash에서 IN_PROGRESS로 업데이트됩니다. 각 스레드에서는 작은 batch 단위의 데이터를 단일 query로 insert하고, 각 query가 성공적으로 수행될 때마다 해당 chunk의 Redis Hash의 last_inserted_pk 값이 업데이트됩니다. Batch가 성공적으로 insert 되어야만 last_inserted_pk가 업데이트 되기 때문에 last_inserted_pk 까지는 반드시 insert가 되었다는 것을 보장합니다.
만약 INSERT query가 수행되고, Redis Hash를 업데이트 하는 과정에서 에러가 발생해 last_inserted_pk가 업데이트 되지 않는 경우 다른 스레드가 해당 chunk를 다시 프로세싱 할 때 duplicate key 에러가 날 수 있습니다. 만약 duplicate key 에러가 발생한다면, 동일한 batch에 대한 INSERT query에 UPDATE ON DUPLICATE KEY를 query에 붙여서 재시도합니다. 최종 형상만 맞으면 되기 때문에 다시 원본에서 가져와 업데이트 해주는 것은 문제가 되지 않습니다. 그 이외의 에러가 발생해 프로세싱이 중단된다면, try-except 블록을 통해 해당 chunk를 다시 Chunk Stack에 반환하고 새로운 chunk를 꺼냅니다. chunk 처리가 정상적으로 완료되면, 해당 chunk의 상태는 DONE으로 업데이트되고 Stack에는 반환되지 않습니다.
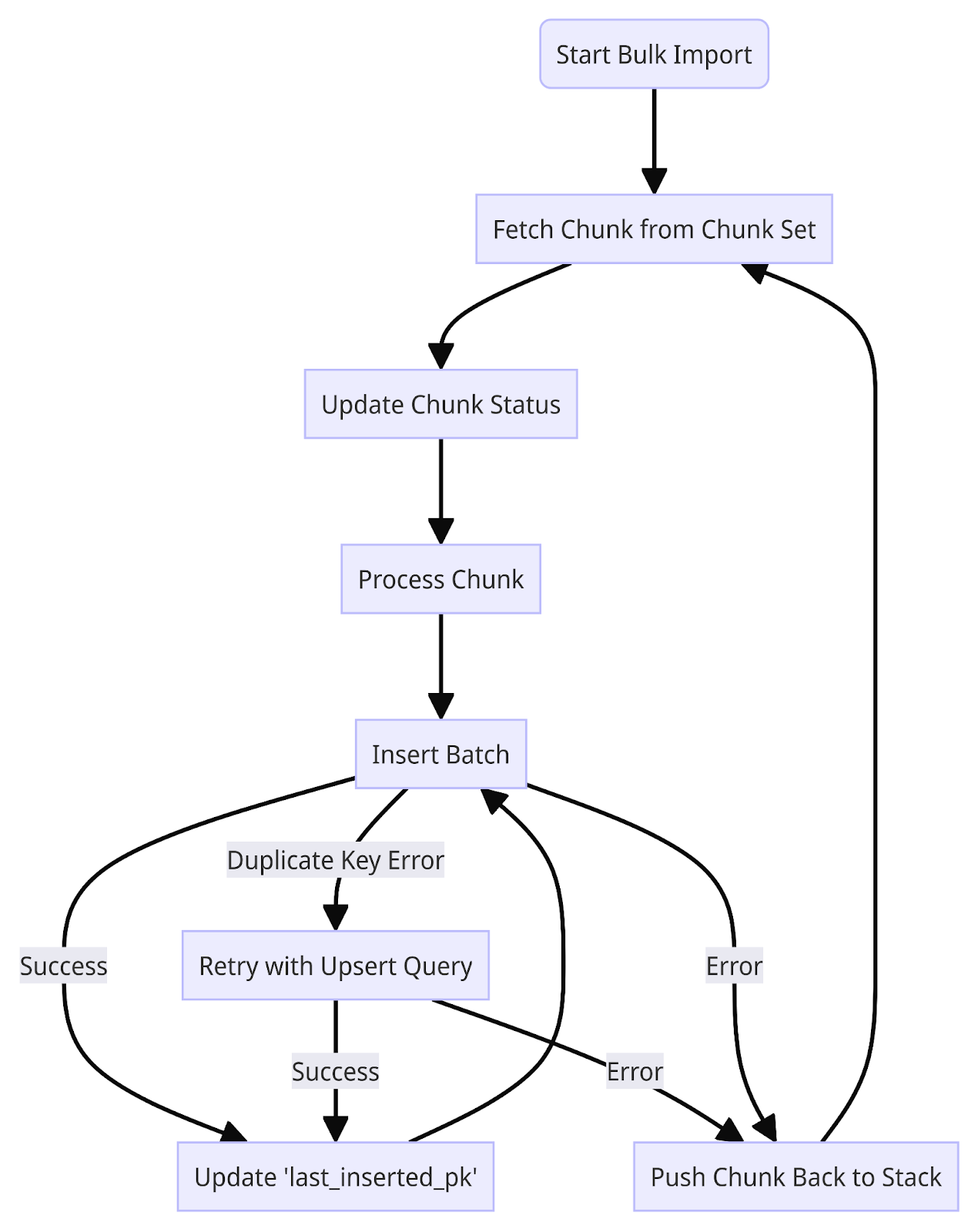
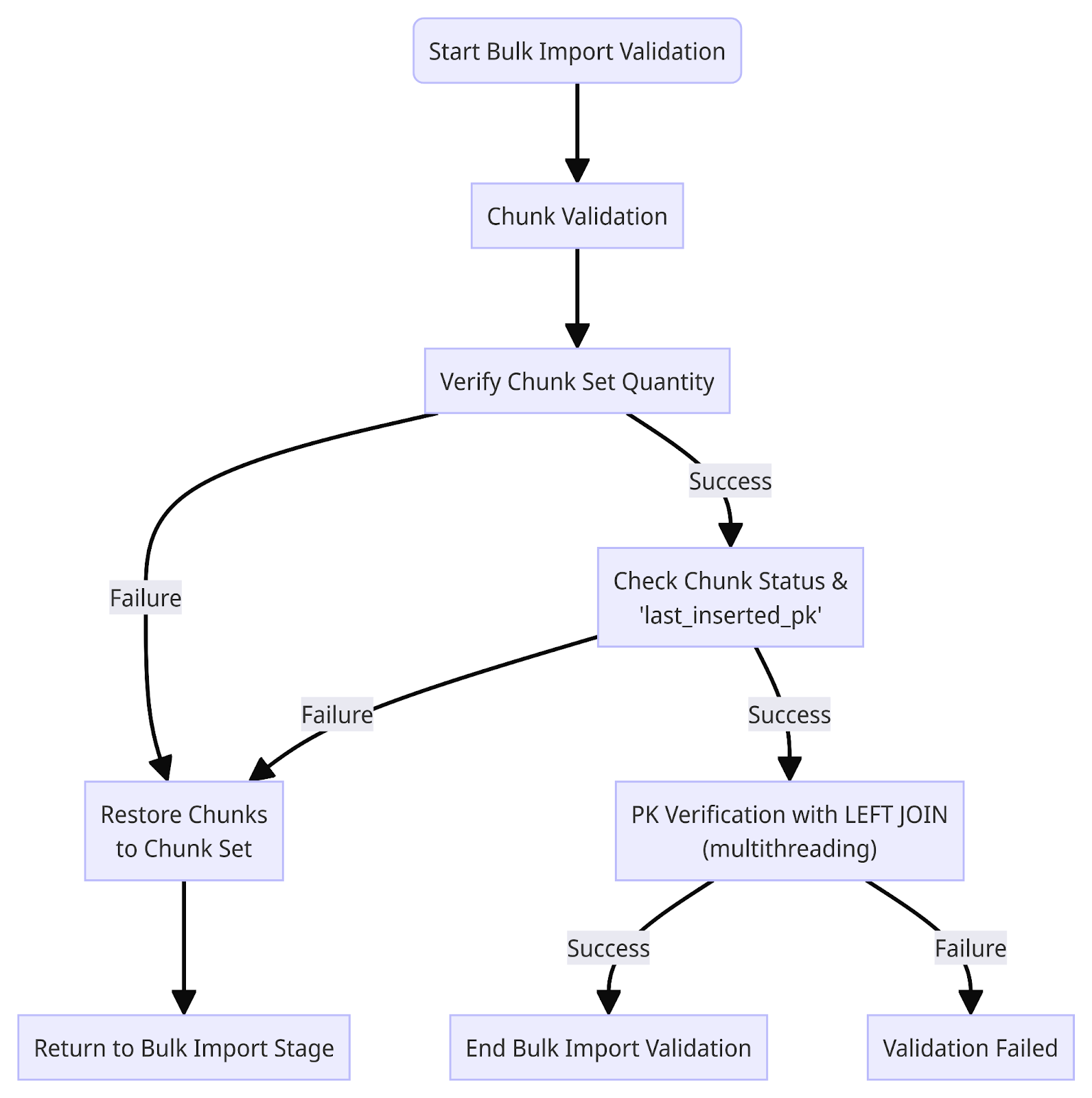
Validation 과정에서는 먼저 Chunk Set에 있는 chunk들이 처음 생성된 수량과 일치하는지 확인합니다. 불일치하는 경우, 데이터베이스에서 정보를 읽어와 복구합니다. 그 다음으로 모든 chunk가 DONE 상태인지, 그리고 각 chunk의 마지막 PK값과 last_inserted_pk가 일치하는지 검증합니다. IN_PROGRESS 상태이거나 last_inserted_pk가 더 작은 경우, 해당 chunk를 다시 Chunk Stack에 추가하여 다시 last_inserted_pk부터 재개할 수 있도록 합니다.
Chunk에 대한 기본적인 검증이 끝난 뒤에는 데이터가 모두 올바르게 복사가 되었는지를 DB에 SELECT query를 이용해 확인합니다. 원본 테이블과 새 테이블의 데이터를 PK range를 나눠 LEFT JOIN하는 query를 멀티스레딩으로 수행하여 전체 구간에 대해 원본 테이블에서 복사가 되지 않은 PK가 있는지를 확인합니다.
데이터 검증 이외에도 프로세스가 DB에 너무 큰 부하를 주지 않게 하기 위한 장치도 마련되어 있습니다. 센드버드에서는 SB-OSC를 AWS환경에서 운영하고 있는데, SB-OSC에는 실행 중인 RDS 클러스터의 CloudWatch 지표를 자체적으로 모니터링 하는 프로세스를 포함하고 있습니다.
이 프로세스를 이용해서 CPU, WriteLatency, DML latency 등이 튀었을 때, 스레드 개수나 batch 사이즈 등을 DB 부하에 맞게 줄이거나 0으로 만들어 임시로 프로세스를 중지하는 기능이 있어 실제 프로덕션 환경에서 트래픽이 들어올 때에도 안정적으로 운영할 수 있습니다.
3. DML 이벤트 반영
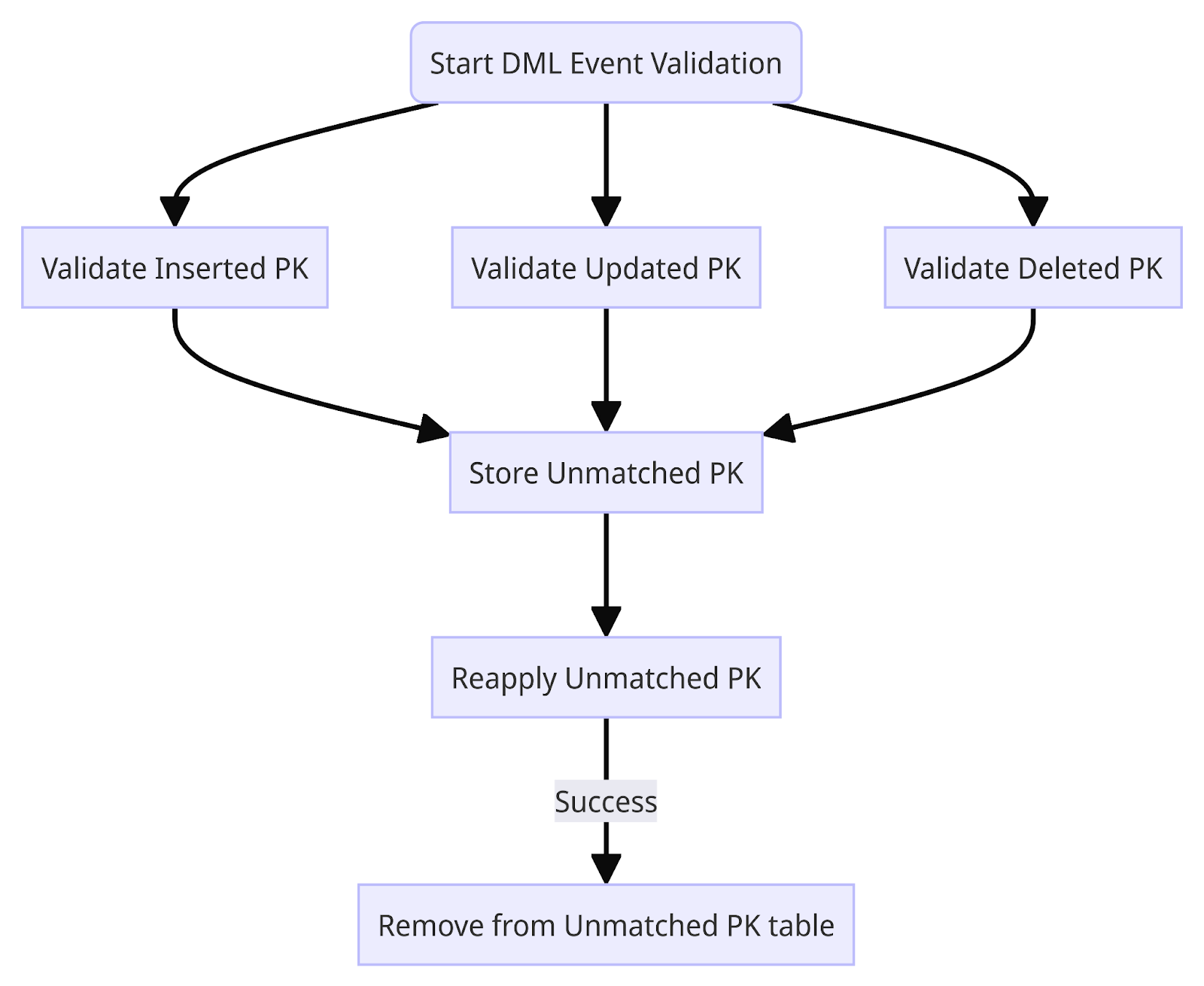
DML 이벤트 반영 단계에서는, 현재까지 발생한 이벤트들이 모두 새 테이블에 정상적으로 반영이 되었는지를 체크하는 정합성 검증을 수행합니다. Bulk import 단계에서 모든 레코드가 성공적으로 복사가 되었음을 보장해주고, binlog 파싱을 통해 DB에 이벤트가 발생한 모든 PK값을 저장하고 있다면 해당 PK값을 갖는 레코드들의 INSERT, UPDATE, DELETE 내역을 새 테이블에서 조사를 하면 라이브 타임에도 DB에 큰 부하를 주는 전체 레코드 비교 없이 효율적으로 데이터 정합성을 체크할 수 있습니다.
INSERT는 원본 테이블에 있는 레코드 중에서 새 테이블에 없는 레코드가 있는지를 체크하고, UPDATE는 원본 테이블에 있는 레코드와 새 테이블에 같은 PK 값을 갖는 레코드의 모든 컬럼의 값을 비교합니다. DELETE가 발생한 레코드는 해당 PK 값을 갖는 레코드가 새 테이블에 존재하는지를 체크합니다. 모든 경우에, 원본 상태를 우선적으로 체크하여 만약 INSERT가 수행되었는데 원본에 없다면 삭제된 것으로 간주하여 새 테이블에 반영하지 않고, DELETE가 수행되었는데 원본에 여전히 존재한다면 다시 INSERT가 된 것으로 판단하여 삭제하지 않습니다.
위 과정을 통해 데이터가 일치하지 않는 PK 값들이 존재한다면, 이 값들을 별도의 테이블에 저장을 하고, 해당 레코드들의 데이터가 일치할 때까지 각각의 INSERT, UPDATE, DELETE를 재시도합니다.
해당 검증은 두 종류의 주기마다 병렬적으로 수행됩니다. 두 종류의 주기에는 마지막으로 검증한 이벤트의 timestamp 부터 현재시간까지 검증하는 주기와, 파라미터에 설정된 시간마다 한 번씩 전체 이벤트에 대해 처음부터 검증하는 주기가 있습니다.
4. 테이블 교체
마지막 테이블 교체 단계는, 현재까지 발생한 모든 DML 이벤트들의 정합성 검증이 종료되고 실시간으로 들어오는 이벤트들까지 순간적으로 모두 처리한 시점에 시도하게 됩니다. 테이블 교체는 세부적으로 다음 과정을 통해 진행됩니다.
모든 이벤트가 반영되고, 데이터 정합성 검증도 완료되었기 때문에 순간적으로 원본 테이블과 새 테이블의 상태가 일치하게 됩니다. 이 때 원본 테이블의 이름을 임시로 변경해서 원본 테이블로의 query를 차단합니다.
그리고 순간적으로 발생한 이벤트들을 모두 처리하고, 순단에 발생한 이벤트들에 대해 데이터 검증 로직을 수행합니다.
Binlog를 전부 읽었다는 것을 보장하기 위해, binlog 파싱 프로세스에서 Redis에 기록한 파싱 완료 시간이 테이블 이름 변경 시점 이후인지를 체크합니다.
위 과정이 모두 성공적으로 3초 이내에 완료되었다면 새 테이블의 이름을 원본 테이블의 이름으로 변경합니다. 그렇지 못하다면 이름이 바뀐 상태로 있는 원본 테이블의 이름을 다시 원래대로 원복합니다.
원본 테이블의 이름이 임시로 변경된 3초 간의 시간 동안 트래픽이 들어오지 않아 에러가 발생할 수 있지만, 이는 기존의 오픈소스 스키마 변경 툴들도 공유하고 있는 문제이기 때문에, 온라인 스키마 변경 자체의 한계점이라고 볼 수 있습니다.
설명된 것과 같이, 각 단계에서 정합성을 위해 필요한 것들을 정확히 정의하고 이를 성취하기 위한 구체적인 장치들을 여럿 만들어 두었기 때문에 다양한 테이블의 상황과 변수들에도 안정적으로 스키마 변경을 수행할 수 있게 됩니다.
Limitations
SB-OSC는 멀티스레딩을 효과적으로 활용하고 중단된 작업의 재개가 용이하기 때문에, 대규모 테이블에서의 대량 DML 처리와 관련하여 기존의 오픈 소스 툴들보다 뛰어난 성능을 제공합니다. 그러나 SB-OSC 역시 몇 가지 한계점을 가지고 있습니다.
1. 정수형 Primary Key 필요성
SB-OSC는 bulk import 단계에서 테이블을 정수형 PK를 기준으로 나누어 멀티스레딩을 수행합니다. 이는 batch 처리 등도 모두 정수형 PK를 기준으로 설계되었기 때문입니다. 그 결과, PK가 정수형이 아닌 테이블에서는 SB-OSC를 사용할 수 없습니다.
2. Primary Key 업데이트 문제
SB-OSC는 PK를 기준으로 원본 테이블의 레코드를 다시 복사하는 형태로 DML 이벤트를 반영합니다. 따라서 테이블의 PK에 업데이트가 발생하는 경우, 데이터의 정합성을 보장하기 어려워집니다.
3. Binlog의 해상도 제한
SB-OSC는 binlog의 해상도가 초(second) 단위라는 점에서 제한을 받습니다. 이는 SB-OSC의 설계 특성상 대부분의 상황에서 큰 영향을 주지 않지만, 초 단위에 과도한 이벤트가 발생하는 경우, timestamp를 기준으로 하는 로직에 일부 영향을 줄 수 있습니다.
4. 소규모 테이블에서의 효율성 저하
소규모 테이블에서는 SB-OSC의 초기 테이블 생성, chunk 생성, 여러 단계로 나뉜 프로세스 등이 오히려 오버헤드로 작용할 수 있습니다. 이는 전체적인 속도를 저하시킬 수 있어, 작은 테이블에 SB-OSC를 적용하는 것은 그다지 효과적이지 않을 수 있습니다.
Performance
SB-OSC는 binlog 파싱과 bulk import 두 구간에서 모두 높은 성능을 보입니다. 다음은 테스트에 사용된 환경 명세입니다. SB-OSC는 AWS Aurora MySQL과 EKS위에서 동작하는 것으로 설계가 되었습니다
AWS Aurora MySQL 클러스터 (v2, v3)
EKS 클러스터
Redis (EKS 위의 컨테이너)
binlog_format: ROW
binlog-ignore-db: sbosc (권장)
SB-OSC는 총 4개의 컴포넌트로 구성되는데, 각각은 별도의 StatefulSet으로 배포됩니다. Binlog를 파싱하는 컴포넌트가 약 2 vCPU를 사용하고 나머지 컴포넌트들은 대부분의 경우에 0.5 vCPU 이하를 점유합니다.
다음은 테스트에 사용한 테이블 스펙입니다. 모든 테이블은 같은 Aurora MySQL v3 클러스터에 있습니다.
테이블 | Avg Row Length (Bytes) | Write IOPS (IOPS/m) |
A | 57 | 149 |
B | 912 | 502 |
C | 61 | 3.38 K |
D | 647 | 17.9 K |
E | 1042 | 24.4 K |
F | 86 | 151 K |
G | 1211 | 60.7 K |
Avg Row Length 는 information_schema.TABLES의 avg_row_legnth 열 이고, Write IOPS 는 performance_schema.table_io_waits_summary_by_table 테이블의 count_write 열 값의 분당 평균 증가량입니다.
Binlog 파싱
다음은 각 테이블에서 발생한 binlog 읽기 속도와, 전체 클러스터에서 binlog가 생성되는 속도를 비교한 차트입니다. Binlog가 생성되는 속도보다 읽기 속도가 빠르다면 발생하는 DML 이벤트들을 실시간으로 잘 읽어낼 수 있다고 해석할 수 있습니다
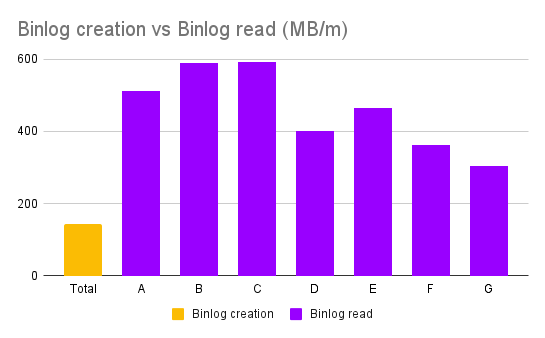
차트에서 볼 수 있듯이, 많은 양의 DML이 발생하는 테이블들에서도 문제 없이 binlog를 파싱하는 것을 확인할 수 있습니다.
Bulk Import
Bulk import는 테이블 A 에서 추가 인덱스와 DML 부하가 없는 상황에서 진행되었습니다. 실제 성능은 인덱스 수, 레코드 개수, 데이터 타입, 트래픽 등에 따라 달라질 수 있습니다.
다음은 인스턴스 사이즈 별 결과입니다.
인스턴스 타입 | Insert 속도 (rows/s) | 네트워크 Throughput (Bytes/s) | 스토리지 Throughput (Bytes/s) | CPU 사용량 (%) |
r6g.2xlarge | 42.3 K | 27.2 K | 457 M | 55.0 |
r6g.4xlarge | 94.0 K | 45.9 K | 900 M | 51.9 |
r6g.8xlarge | 158 K | 72.2 K | 1.39 G | 44.6 |
Insert 속도, 네트워크 Throughput, 스토리지 Throughput 는 CloudWatch 메트릭을 기반으로 계산되었습니다.
gh-ost와 비교
기존 스키마 변경 툴과의 성능을 비교하기 위해, 동일한 조건 내에서 SB-OSC와 gh-ost 의 전체 작업 시간을 비교해 보았습니다. gh-ost도 SB-OSC와 같이 binlog를 파싱해서 DML 이벤트를 가져오기 때문에 비교군으로 채택되었습니다. 다음은 테스트 환경 명세입니다.
약 2억 개의 레코드가 있는 테이블 C
Aurora MySQL v3 클러스터, r6g.8xlarge 인스턴스
인덱스 2개
batch_size (gh-ost는 chunk-size): 50000
(gh-ost) --allow-on-master
추가 DML 부하가 없는 경우
스키마 변경 툴 | 전체 작업 시간 | CPU 사용량 (%) |
SB-OSC | 22분 | 60.6 |
gh-ost | 1시간 52분 | 19.7 |
추가 DML 부하 발생 시
작업 시간 동안 추가 DML 부하는 테이블 C에만 발생시켰습니다. (~1.0K inserts/s, ~0.33K updates/s, ~0.33K deletes/s)
스키마 변경 툴 | 전체 작업 시간 | CPU 사용량 (%) |
SB-OSC | 27분 | 62.7 |
gh-ost | 1일+ | 27.4 |
gh-ost의 경우 약 50% (~12h) 진행률인 상황에서 ETA가 계속 늘어나고 있어 작업을 중단했습니다.
SB-OSC는 큰 DB 인스턴스가 제공하는 CPU를 충분히 사용하여 높은 insert throughput으로 데이터를 복사할 수 있었습니다. DML 이벤트 반영 단계의 최적화로 인해, 추가 DML 부하가 발생하는 환경에서는 기존 스키마 변경 툴과 더 큰 차이를 보여줍니다.
Conclusion
센드버드의 DB 구조는 스키마 변경을 많이 요구하는 환경입니다. Chat만 해도 DB가 40개가 넘기 때문에 대형 리전들에서의 스키마 변경은 항상 큰 부담으로 다가왔습니다. 이 과정에서 저희는 pt-osc를 기존에 쓰고 있었지만 그 과정에서 수 차례 작업을 중단하기도 하고, 트리거를 생성하면서 장애를 맞기도 하여 많은 어려움이 있었습니다.
SB-OSC의 기본적인 프로세스는 사실 저희 DBA 분들이 오랜 경험을 바탕으로 얻은 노하우를 기반으로 매번 해당 리전의 트래픽이 낮은 시간대에 손으로 몇 주간 작업하시던 것을 코드화 한 것입니다. 작업 전체 시간으로 봤을 때도 수 개월이 걸리던 문제를 며칠 내로 끝낼 수 있었기 때문에 엄청난 발전이지만, 저희 팀원 분들의 힘든 작업을 자동화했다는 것에도 큰 의의가 있습니다.
이 툴을 이용해서 저희는 2023년 한 해동안 현재까지 센드버드에서 진행된 스키마 변경 중 최대 규모의 스키마 변경들을 성공적으로 마무리할 수 있었습니다. 수십 테라바이트에 달하는 테이블을 수 일 내로 작업할 수 있는 SB-OSC의 도움이 없었다면 결코 정해진 시간 내에 마무리할 수 없었을 것입니다.
현재 센드버드 DB에 여전히 많은 양의 스키마 변경 작업이 남아있기 때문에, 앞으로도 SB-OSC를 적극적으로 활용할 수 있을 것으로 기대가 되고, 그동안 스키마 변경 작업이 불가능하여 하지 못했던 DB의 구조적인 개선도 향후 진행할 수 있을 것으로 기대 됩니다.
자세한 내용은 저희 소스 코드를 통해서 확인하실 수 있습니다








