
GCP에서 Datawarehouse Governance 구축하기(feat. BigQuery) 1편


BigQuery 도입 배경
본론에 앞서 어떤 배경으로 Datawarehouse를 구축하게 됐는지를 간단히 공유하려고 합니다. 기존에 Sendbird는 1차 가공된 Product 데이터와 여러 데이터 소스들(Dashboard, Salesforce, Marketo, Greenhouse 등)을 사용해서 만든 PostgreSQL 데이터 마트를 Looker(BI solution)에 연결해서 데이터 분석 및 대시보드를 운영하고 있었고, 로그 데이터들은 AWS Athena를 사용하여 조회해서 사용하고 있었습니다. 이러한 구조에는 다음과 같은 문제점들이 있었습니다.
- 로그 데이터와 DB 데이터 등 다양한 데이터를 한 곳에서 조회하기 어렵다.
- Log data와 정제된 데이터들을 join 해서 함께 분석할 수가 없다.
- 사이즈가 큰 데이터의 경우 조회하는 데 시간이 너무 오래 걸린다.
이런 문제를 해결하기 위해 PB 단위의 Raw data부터 MB 수준으로 가공된 데이터까지 하나의 저장소에 저장하고 프로세싱 할 수 있는 저장소가 필요하다는 결정을 내리게 됐고, 여러 제품을 POC한 결과 BigQuery를 사용해서 Datawarehouse를 구축하게 됐습니다. Datawarehouse 솔루션은 한 번 정해지고 나면 추후 변경이 쉽지 않기 때문에 시중의 여러 솔루션 중 BigQuery를 선정하기까지 다양한 항목을 도출하여 신중하게 검토하였습니다. 다음에 기회가 되면 Sendbird에서 Datawarehouse 솔루션을 선정한 과정을 포스팅 하여 보도록 하겠습니다. (기대해주세요!)
Introduction
많은 분이 아시는 것처럼 BigQuery를 사용하여 Datawarehouse를 구축하기 위해서는 많은 부분을 고려해야 합니다.

대표적인 요소는 아래와 같습니다.
- Project structure
- Security
- IAM
- Audit
- VPC
- Monitoring
- Performance
- Cost(Slot usage)
- Performance
- Table 구조
- Partitioning & Clustering
- Table Schema Management
- Resource Management
- Terraform
- Python
전체 부분 중에서 1편에서는 Project Structure, Security, Monitoring에 대해서 먼저 소개하겠습니다.
이제부터 Sendbird에서는 위와 같은 부분들을 어떻게 구축해서 사용하고 있는지 하나하나 살펴보시죠!
Project Structure
The only UIKit you need.
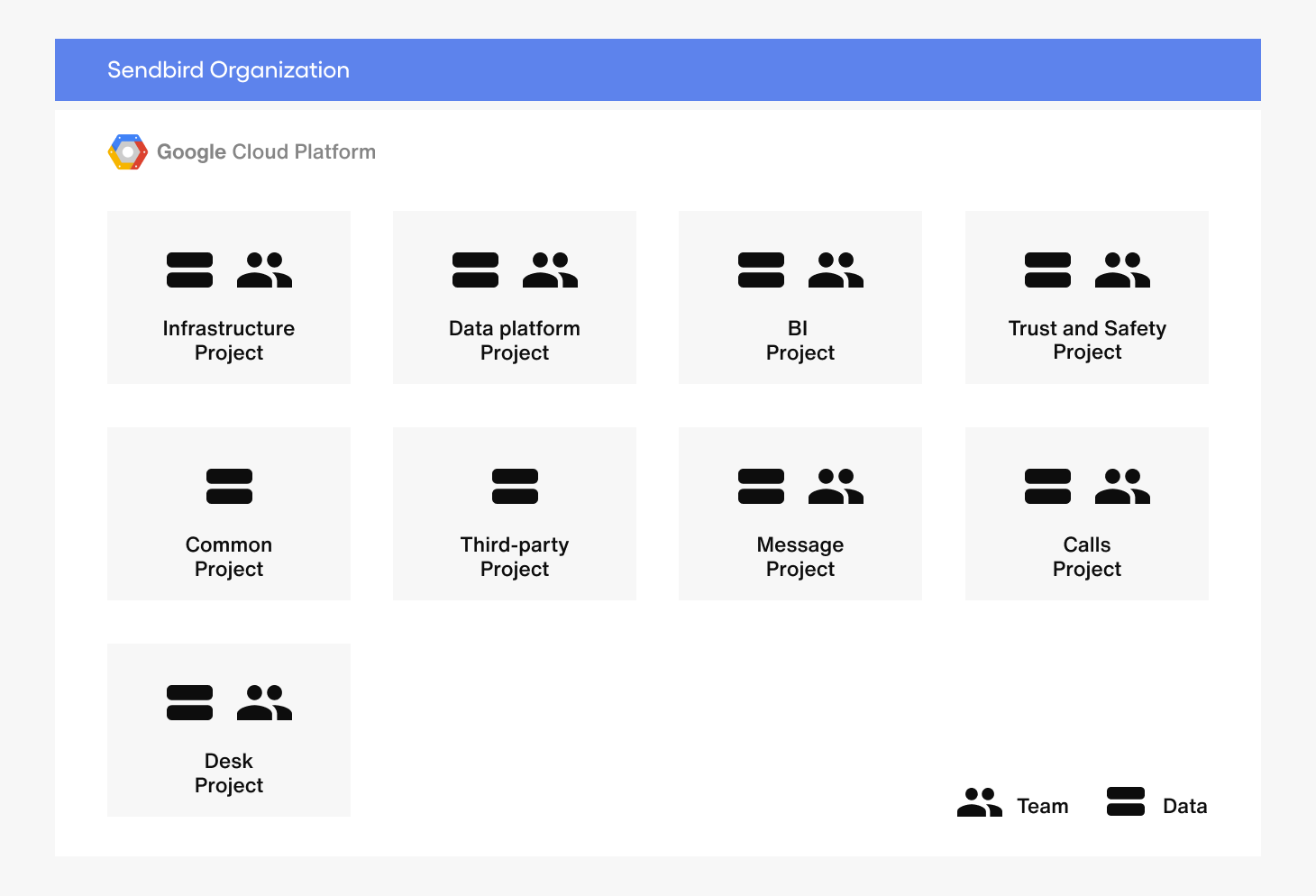
Project는 GCP에서 굉장히 중요한 단위입니다. (AWS의 Account와 비슷한 개념적 단위.) 특히, BigQuery에서는 Project 단위로 Team 별 Data access를 나누고, Slot을 나눠서 할당해서 사용할 수 있기 때문에 더욱 중요합니다.
저희는 두 가지 기준으로 Project를 나눴습니다.
- Data의 성격
- Team 단위
이렇게 두 가지 기준으로 데이터를 나눈 이유는 다음과 같습니다.
먼저, Data 단위로 Project를 나눈 이유는 각 팀이 필요한 데이터만 access 할 수 있도록 설계하기 위해서 입니다. 그리고 Team 단위로 Project를 나눈 이유는 각 팀의 Data-driven Decision Making을 가능하게 하고, 팀별로 slot을 나눠서 할당해서 리소스 관리도 가능합니다.
예를 들어서, 위와 같이 프로젝트를 나눴다고 가정하고, 다음과 같은 User 시나리오를 생각해보겠습니다.
BI팀의 Jordan이 AWS cost와 고객의 message 발생량을 사용하여 message량과 AWS server 비용 간의 correlation을 찾는다고 가정하면, message 데이터가 들어 있는 Message Project와 AWS resource 데이터가 들어 있는 Third-party Project에 각각 접근하여 데이터를 가져와서 BI Project에서 데이터들을 조합하여 새로운 Dataset을 만들 수 있습니다. 이렇게 각 팀은 접근 가능한 타 Project의 데이터들을 가져와 분석할 수 있는 환경을 구성할 수 있기 때문에 원본 데이터를 보호할 수 있습니다. 예를 들어 Messaging팀만이 Message Project에 write 권한을 가지게 됩니다.
회사가 성장함에 따라 팀이나 제품의 수가 증가하더라도 각 담당자가 필요로 하는 데이터들을 쉽게 찾고 접근할 수 있고, 관리자는 이를 유연하게 제어 할 수 있도록 Project를 설계하는 것을 가장 중점적으로 고려하였습니다. 이 부분은 Data Platform팀의 manager Taeyeon께서 Amazon에서 접한 Datawarehouse에 대해서 경험과 생각을 나눠 주셔서 반영하게 됐습니다. 정말 감사합니다. 🙂
Security
다음은 security입니다. B2B Software에서 security는 가장 중요한 부분 중 하나입니다. Sendbird에서는 새로운 기술이나 solution을 도입할 때 항상 security 측면에서 충분히 안전한지, 접근 제어 및 logging 등 필수적인 항목들은 어떻게 구축해야 하는지 먼저 검토하고 있습니다.
IAM
IAM Resource 같은 경우는 다음과 같은 3가지 사항을 적용 했습니다.
resource "google_project_iam_member" "data_platform_group_data_viewer" {
project = var.gcp_project
role = "roles/bigquery.dataViewer"
member = format("group:%s", local.group_mail_facts.data_platform)
}
resource "google_project_iam_member" "data_platform_group_job_user" {
project = var.gcp_project
role = "roles/bigquery.jobUser"
member = format("group:%s", local.group_mail_facts.data_platform)
}
- G Suite의 Group을 사용해서 권한을 부여하기 때문에 새로운 팀원이 입사하거나 퇴사할 때 따로 관리할 부분이 없도록 하였습니다.
- Production에서 개인 user들은 Read 권한을 가지고 있고, 실제 데이터를 write 하는 것은 application의 service account에서만 할 수 있도록 구성하였습니다.
- 각 Application에서 사용하는 service account를 반드시 나눠서 사용.
- 각 팀의 Application의 Service account
- Looker의 SQL Runner Service account
- Looker의 Dashboard Service account
- Monitoring Application Service account
- ETC
Audit
Auditing은 ISO27001, SOC2와 같은 Compliance를 준수하기 위해서는 필수입니다.
이 부분을 위해서 고려한 부분은 두 가지 입니다.
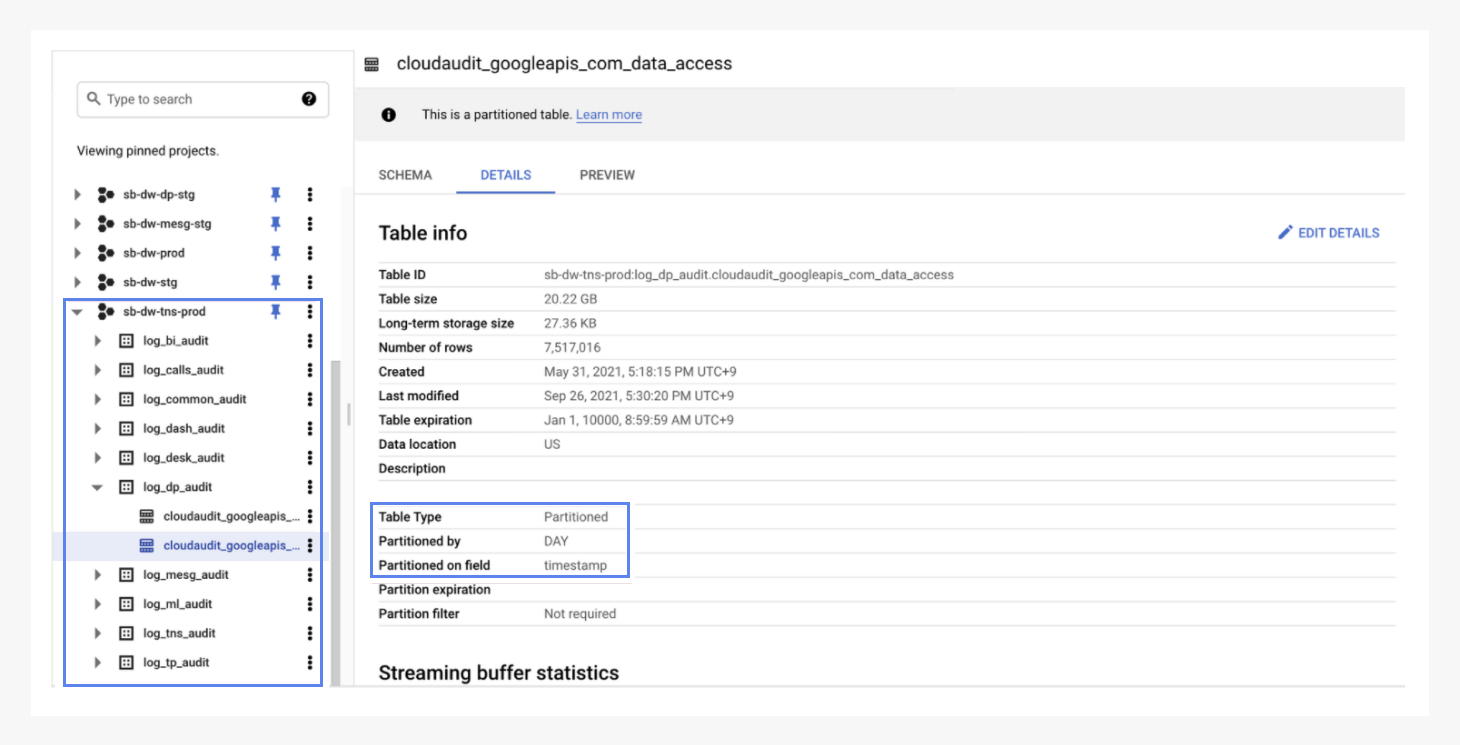
- 비용 관리를 위해 Data retention을 위해서 partitioning
Log 같은 경우는 눈 깜빡할 사이에 많은 데이터가 쌓이게 됩니다. 이는 곧 각종 비용이 증가하는 문제로 직결됩니다. Sendbird에서는 내부 규정에 따라서 retention을 설정하고, 관리의 편의를 위해서 초기부터 Daily로 partition을 나눴습니다.
- T&S팀이 스스로 log를 확인할 수 있는 환경 구축
Sendbird에서는 GCP Log Router의 sink를 통해서 각 프로젝트의 로그가 자동으로 T&S팀의 프로젝트로 저장되도록 하였습니다. T&S팀은 적절한 쿼리를 통해 언제든 직접 로그를 확인할 수 있습니다.
VPC
Security의 마지막 파트인 VPC입니다.
resource "google_access_context_manager_access_level" "bigquery_staging" {
parent = format("accessPolicies/%s", google_access_context_manager_access_policy.access_policy.name)
name = format("accessPolicies/%s/accessLevels/%s", google_access_context_manager_access_policy.access_policy.id, var.bigquery_staging_access_level_name)
title = "bigquery-staging"
basic {
conditions {
ip_subnetworks = concat(
[
# vpn
local.network_cidr.vpn.kr,
local.network_cidr.vpn.us,
local.network_cidr.vpn.paloalto-ap-dev,
local.network_cidr.vpn.paloalto-us-dev,
],
# airflow
local.network_cidr.airflow_staging_cidr.use1,
local.network_cidr.airflow_staging_cidr.apne2,
# fivetran
local.network_cidr.fivetran.us,
# looker
local.network_cidr.looker.asia
)
}
}
}
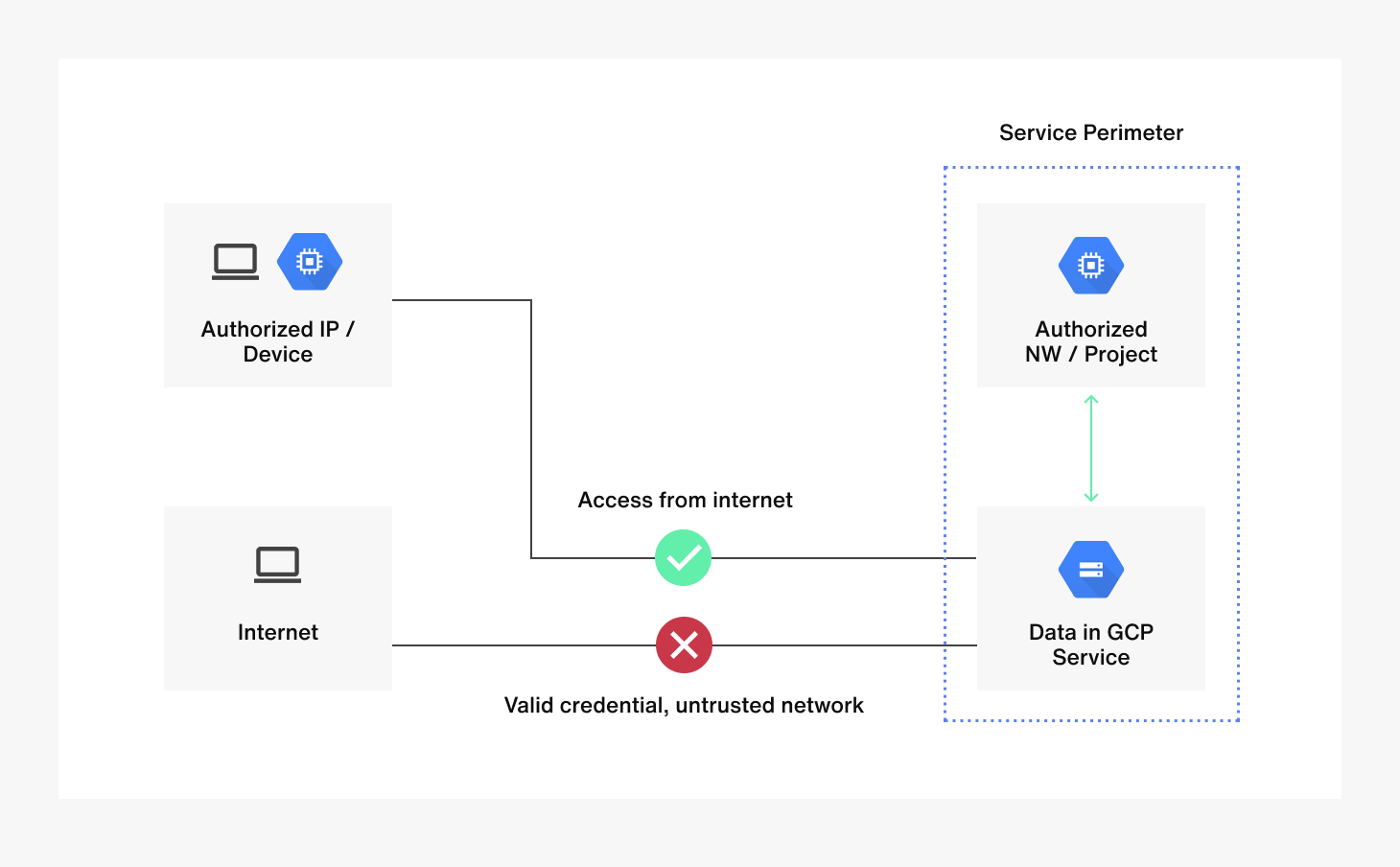
물리 보안은 매우 중요합니다. ID나 password와 같은 secret들은 언제든지 노출될 수 있기 때문입니다. Sendbird에서는 GCP의 Access Context Manager와 VPC Service Controls를 통해서 ingress rule을 적용하여 사내 VPN, 그리고 데이터 접근이 필요한 Application IP (Airflow의 NAT Gateway IP 등)에서만 접근이 가능하도록 설정하였습니다. 위는 staging을 구성했던 Terraform 예시 코드입니다.
VPC Service control에 대해서 자세한 설명이 필요하신 분들은 아래 문서를 참고하시면 좋을 것 같습니다.
https://cloud.google.com/vpc-service-controls/docs/overview
위에서 함께 살펴본 것 처럼 Sendbird에서는 Project 구조, auditing, VPC 등을 구축하여 데이터를 보호하고 있습니다.
Monitoring
1편의 마지막 Part인 monitoring입니다. monitoring은 안정적인 운영을 위해서 가장 중요한 부분입니다. Monitoring이 구축되지 않았다면 해당 프로젝트는 완료된 프로젝트라고 하기 어렵습니다.
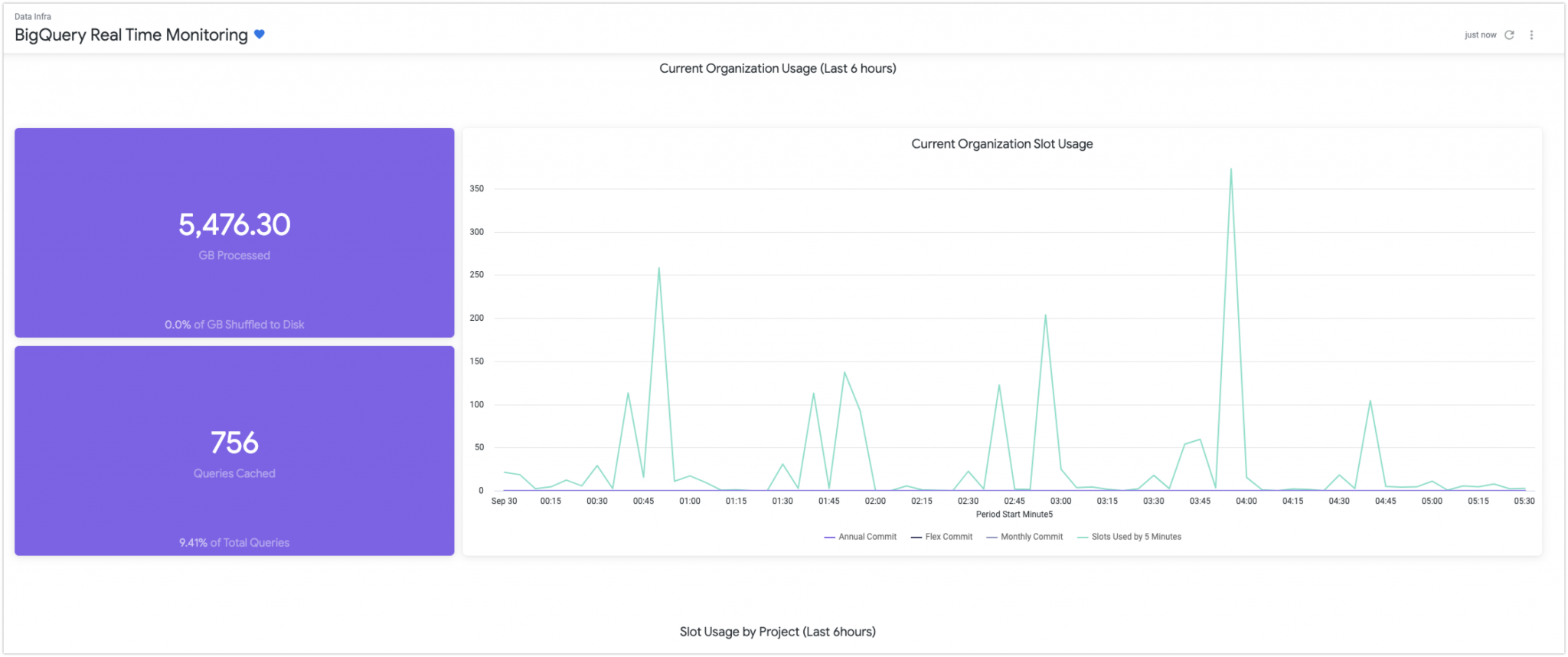
Monitoring을 구축하면서 집중한 부분은 performance와 cost입니다.
- 효율적인 Query들이 사용되고 있는지
- ex. Disk에 shuffle 된 데이터가 있는지 체크해서 현재 미리 구입한 slot의 양보다 더 큰 연산이 있는지
- Slot의 수요 예측을 위해서 slot monitoring
- ex. 실시간 slot monitoring을 통해 on-demand로 구입해서 cost 절약이 가능합니다.
- Project별 slot usage를 이용해서 팀별 필요한 resource 체크
monitoring을 위해서는 dashboard와 alert이 가장 중요한데 Sendbird에서는 Looker라는 BI service를 사용하고 있었기 때문에 Looker라는 BI service를 사용하여 dashboard를 구축하였습니다.
이제 어떤 데이터를 사용해서 dashboard를 구축했는지 살펴보겠습니다. BigQuery에서는 Information_schema는 아래와 같은 metadata를 제공합니다.
해당 schema에 대한 자세한 내용은 여기를 살펴보시면 좋을 것 같습니다.
https://cloud.google.com/bigquery/docs/information-schema-intro
Sendbird에서는 실시간에 가까운 usage를 모니터링 하기 위해서 BigQuery의 information_schema를 LookML로 구현해 놓은 오픈소스인 bq_info_schema_block 프로젝트를 사용해서 dashboard를 구축하였습니다. 도움이 되는 여러 가지 dashboard를 미리 구축해 놓았기 때문에 바로 사용해도 되고, 목적에 따라 customize 하여 사용하셔도 됩니다.
https://github.com/looker/bq_info_schema_block
지금 까지 BigQuery로 Datawarehouse Governance 구축을 위해 필요한 부분 중에
- Project Structure
- Security
- Monitoring
를 살펴봤습니다.
궁금하신 부분이 있으면 편하게 댓글이나 메일 주세요. 또, 해당 분야에 관심이 있는 분이라면 Sendbird에서 함께 더 나은 Datawarehouse를 만들어 나갈 수 있으면 좋겠습니다!
그럼 2편에서 뵙겠습니다!










