
Infrastructure Management using Terraform
안녕하세요. 저는 인프라스트럭처 엔지니어로 일하고 있는 Eden이라고 합니다.
센드버드의 인프라스트럭처의 현황과 인프라스트럭처 관리 툴을 Terraform으로 정착하게 된 스토리를 전해드리려고 합니다.
Intro
시작하기에 앞서 센드버드의 인프라스트럭처(줄여서 앞으로 인프라 라고 하겠습니다.)의 현황과 인프라 관리에 대해 먼저 말씀드리려고 합니다.
2020년 5월부터 사용 중인 총 EC2 Instances 개수 들입니다.
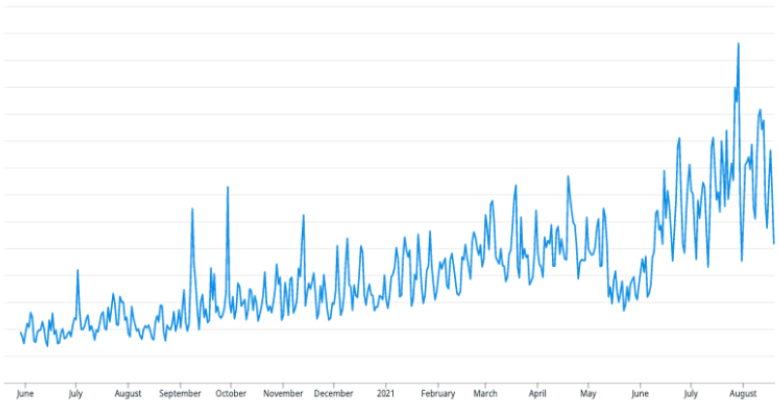
센드버드를 사용하고 계신 고객들의 데이터를 안전하게 처리하고 관리하기 위해 고객별 인프라를 네트웍 레벨에서 격리해왔습니다. 입사할 당시만 해도 8개의 AWS region을 사용 중이었으며 그 이후에 11개로 늘었으며 인프라 규모 또한 초기에 비해 리소스가 약 1.5배로 증가했고 앞으로도 더 증가할 것입니다.
다음 자료는 사내에서 발표하기 전 알아봤던 현재 사용 중인 AWS 리소스 목록입니다.
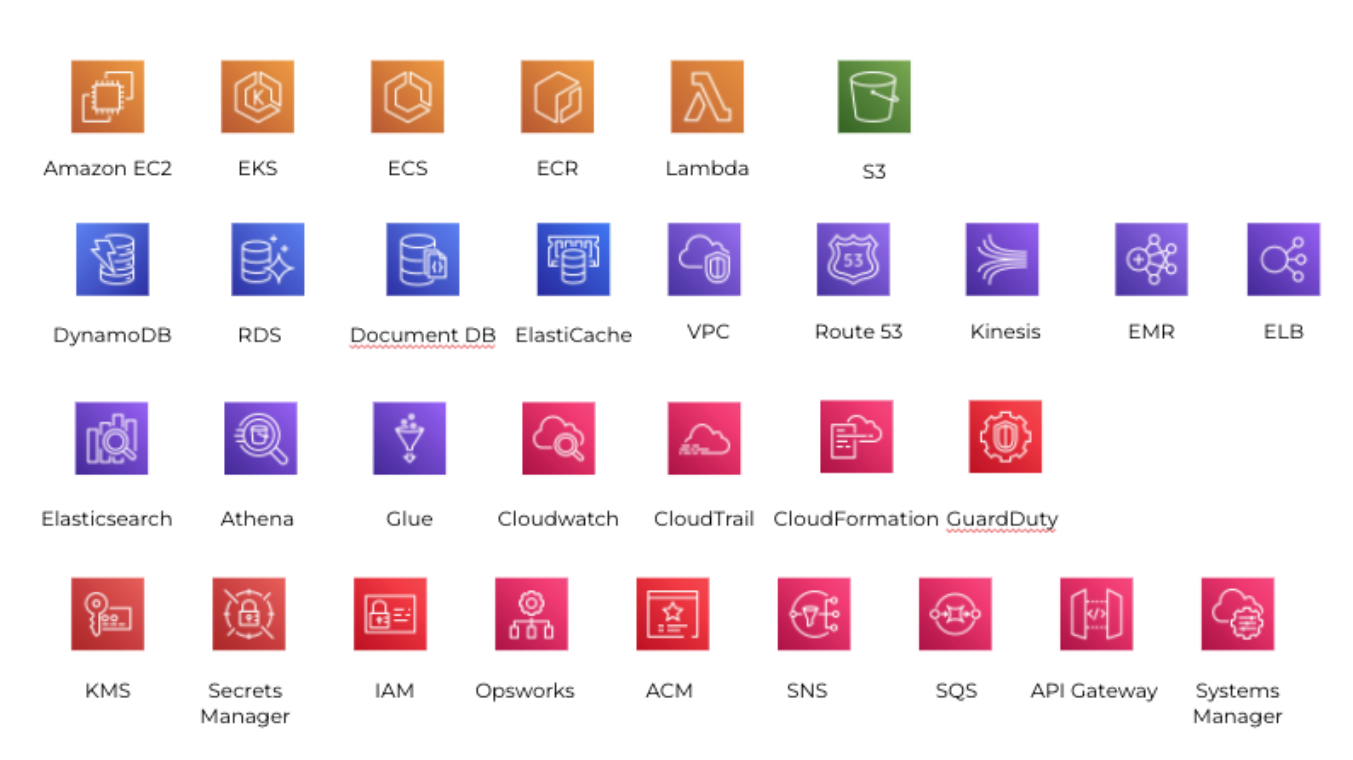
AWS 리소스들 종류의 증가뿐만 아니라 사용 중인 내부 리소스들 또한 사업이 확장됨에 따라 급증하고 있습니다. 다양한 종류와 기하급수적으로 늘어나는 리소스들을 관리하는 것은 여타 우리 회사만의 문제만은 아닐 것입니다.
인프라 엔지니어들은 점차 늘어나는 새로운 자원들을 관리하게 됩니다. 그리고 아키텍처적인 이슈에 의해 현재의 인프라를 완전히 바꾸기도 합니다. 또한 어떤 사유든 간에 관리영역 밖에 있던 자원들을 찾아내 관리 영역 안으로 끌어들이기도 합니다.
우리가 익히 들어본 “대규모의 인프라”를 경험하기 이전에 보통은 작은 서비스 형태를 서버에 띄우고 서버를 죽이면서 관리를 할 것입니다. 물론 전체적인 설계를 하지만 시행착오를 거치면서 만들고 부수고를 반복하게 됩니다.
이렇게 반복적으로 우리의 application과 맞춰가게 되면 인프라는 견고해질 것입니다. 견고해지는 시점이 오게 되면 보통은 비즈니스적인 이유로 인프라를 확장해 나가기 시작합니다.

처음 견고하게 만들었던 인프라와 비슷한 형상을 가지지만 비즈니스적으로 고객의 요청 또는 요구사항을 만족시키기 위하여 인프라 리소스가 추가되거나 수정되거나 삭제될 수 있습니다. 다양한 요구사항을 만족시켜야 하고 갑작스러운 변화에 잘 대응하기 위해서 인프라 엔지니어들은 다음과 같이 항상 고민하고 도전 및 시도를 하게 됩니다.
- 인프라는 유연하게 변할 수 있어야 합니다.
- 리소스들을 잘 추적 할 수 있도록 Observability를 마련해야 합니다.
- Cost를 효율적으로 사용하기 위한 방안이 무엇인지 찾아야 합니다.
- 보안정책을 어떻게 수립할지 정해야 합니다.
그래서 모든 인프라 엔지니어들은 항상 이 상황을 꿈꿉니다.

하지만 현실은 그렇지 않습니다. 이슈는 어디에나 있고 문제는 언제나 터지기 마련이죠.

하지만 제가 겪었던 경험과 그리고 주위 엔지니어들의 말을 빌려 말씀드리자면
“현실은 아니지만, 인프라 엔지니어는 이상과 같이해내고야 만다” 입니다.
The only UIKit you need.
과거의 인프라
격변의 시기
과거 센드버드 인프라는 CloudFormation을 이용해서 리소스들을 생성하여 격리된 환경의 거대한 인프라를 만들어냈습니다. CloudFormation을 콘솔에서 만들지 않고 리소스를 Jinja 템플릿화했습니다. 그리고 저희 팀에서 운용했던 in-house솔루션을 이용해서 템플릿과 환경설정을 이용하여 yaml파일을 만들고 배포했습니다.
하지만 하나의 격리된 환경을 만들기까지 여러 문제점들과 불편한 점들이 존재했습니다.
Tightly coupled architecture
magpie라는 툴이 CloudFormation 템플릿과 어플리케이션 환경설정 값들을 가지고 인프라가 생성됩니다. 그래서 환경설정값이 바뀌거나 CloudFormation 템플릿이 바뀔 때 바로 적용이 되어야 했었습니다.
하지만 이 두 가지를 만족시키기 위해 magpie 코드도 변경이 됐어야 했었습니다. 이는 장애 상황시 환경설정이 제대로 세팅이 되었는지, CloudFormation 템플릿이 제대로 바뀌었는지, magpie는 이를 모두 수용하고 있는지, 실행시 문제는 없는지 모두 검증이 됐어야 했습니다.
변경할 때 마다 트러블 슈팅을 했어야 했고 이는 또다른 부담감으로 다가왔었습니다.
끝나지 않는 설정
CloudFormation 으로 모든 격리된 환경 셋업이 된다면 정말 다행이지만 시간이 지날 수록 AWS가 아닌 리소스들이 늘어났고 해당 리소스들을 한땀한땀 만들어줘야 했습니다. 그리고 만드는 과정을 문서로 남기지만 셋업당시의 사람 기억에 의존했습니다.
사람 기억에 의존하는 리소스 관리
급한 장애 상황이나 필요에 의해서 AWS console을 통해 리소스 변경이 이루어 질 수 있습니다. 하지만 이를 CloudFormation 템플릿에 적용을 바로 해야하지만 못하게 되고 작업자가 한 명이 아니라 여러 명이기 때문에 히스토리가 쌓여서 결국 변경해야 하는 포인트가 쌓여 적용하지 못하거나 사람들의 기억에 의존하게 됩니다.
위와 같은 문제들을 발견하게 되었고 고착화되어있는 작업들이 많았습니다. 저는 이런 작업 절차들과 문제점들을 바꾸고 싶었습니다.
작업을 사람 기억에 의존하고 수동으로 업데이트하는 것이 아니라 인프라 이면서 동시에 문서도 되고, 코드가 바뀌어야 인프라가 바뀌는 작업환경을 만들고자 했습니다.
현재의 인프라
Why IaC? Why Terraform?
과거와 현재의 인프라를 구축함에 있어서 꼭 지키고자 했던 것이 있습니다.
“코드가 우선이다”
인프라가 사람에 의해 바뀌어도 코드가 우선이기 때문에 코드를 다시 적용하여 코드와 인프라를 맞춰주거나 코드를 업데이트 해야합니다. 이를 만족시키고 아래 여러 장점들을 우리는 필요로 했기 때문에 CloudFormation에서 Terraform 으로 IaC 툴을 변경했습니다.
첫 번째 장점으로는 dry-run을 통해 실행 전 결과를 볼 수 있다는 점입니다. 바로 리소스가 만들어지는 것이 아니라 실행 전 어떻게 만들어지는지 또는 어떻게 변경이 되는지를 dry-run결과를 보고 알 수 있습니다.
두 번째는 state파일이라는 것으로 현재 코드와 실제 반영된 리소스들을 비교할 수 있습니다. 파일형태는 json 타입이고 Terraform을 통해 적용이 되면 어떤 리소스가 만들어지는지 Terraform state 파일로 만들어집니다. Terraform은 state file과 AWS에 존재하는 리소스를 비교해줍니다. state파일은 s3 bucket에 올리거나 local file로 이용할 수 있습니다. 그리고 state file은 lock을 걸 수 있도록 기능을 제공하고 있으며 한 인프라를 동시에 여러명이 작업하지 못하도록 합니다.
세 번째는 다양한 제품군을 IaC화 할 수 있는 provider라는 것을 제공하고 있다는 점입니다. 모든 격리된 환경 셋업 이후 AWS가 아닌 리소스들을 셋업했어야 했습니다. 대표적인 예로 알람을 받을 수 있는 PagerDuty, 모니터링을 할 수 있는 DataDog 그리고 배포 담당 툴인 Spinnaker 입니다. 이들 또한 Terraform에서 제공하는 provider로 셋업이 가능했습니다.
Re-usable Module
하나의 격리된 환경을 생성하기 위해서 필요한 연관된 자원들이 사실 많습니다.
그래서 저희는 다음과 같이 대표적인 모듈을 기본으로 사용하고 이외에 다양한 모듈들과 리소스들을 모아 하나의 큰 core 모듈을 만들었습니다.
- VPC 모듈 : Network layer에 해당하는 vpc, subnets, Internet G/W, NAT G/W, Routing table, 당연히 하나 필요로 하는 bastion server등, VPC로 묶을 수 있습니다.
- EKS 모듈 : Kubenetes 클러스터를 올리기 위해 Cluster와 oidc provider, nodegroup, controller를 위한 iam role, policy등을 EKS 모듈로 묶습니다.
- Server group 모듈 : ASG나, LB 등 인스턴스와 관련된 리소스들도 필요에 따라 각각 또는 합쳐서 쓸 수 있기 때문에 server group 모듈로 묶었습니다.
모듈은 이곳/저곳에서 재사용이 가능하도록 구현을 해야 합니다. 그리고 외부에서 필요로 하는 플래그, 변수들을 주입받을 수 있도록 적절히 잘 추상화 된 모듈을 설계하고 구현해야 합니다.
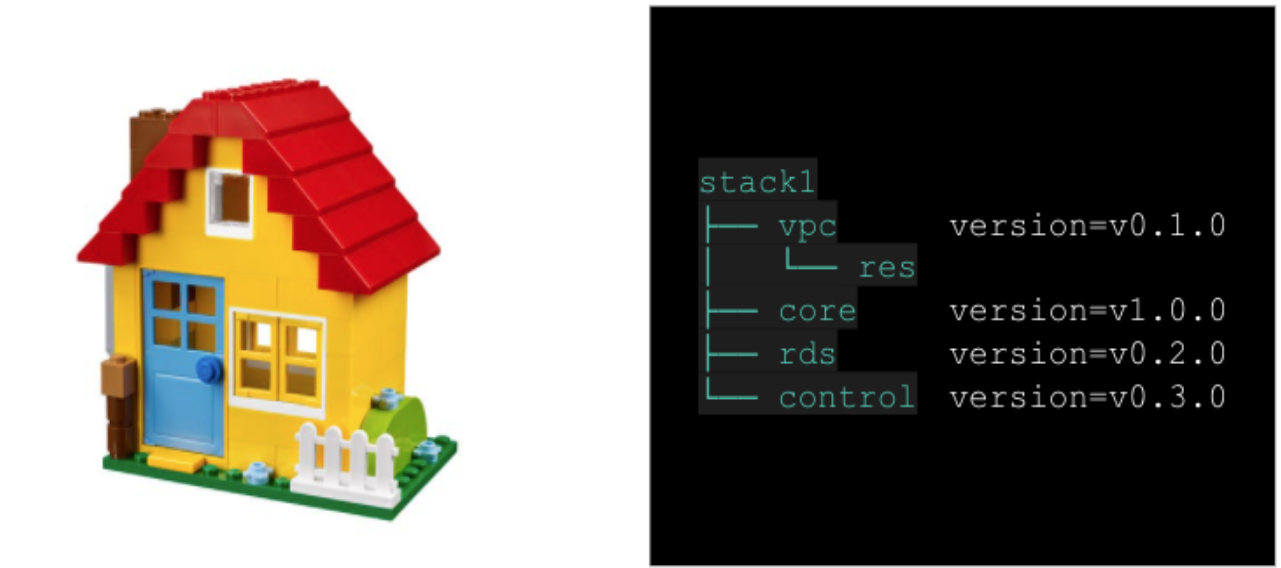
다음과 같이 설계가 된 모듈들은 고유의 버전을 가지게 되고 사용자는 필요한 버전을 사용만 하면 됩니다. 외부에서는 이 대표 버전만 믿고 쓰면 되는거고, 이 내부의 상세 구성을 알 필요도 없고 또 그렇게 관리해야 합니다

이렇게 모듈을 준비가 됐다면 새로운 격리된 환경을 만들어 볼 수 있습니다. 위 core모듈 1.0.0버전과 나머지 필요한 모듈들의 버전들을 명세한다면 끝입니다.
Apply with Automation
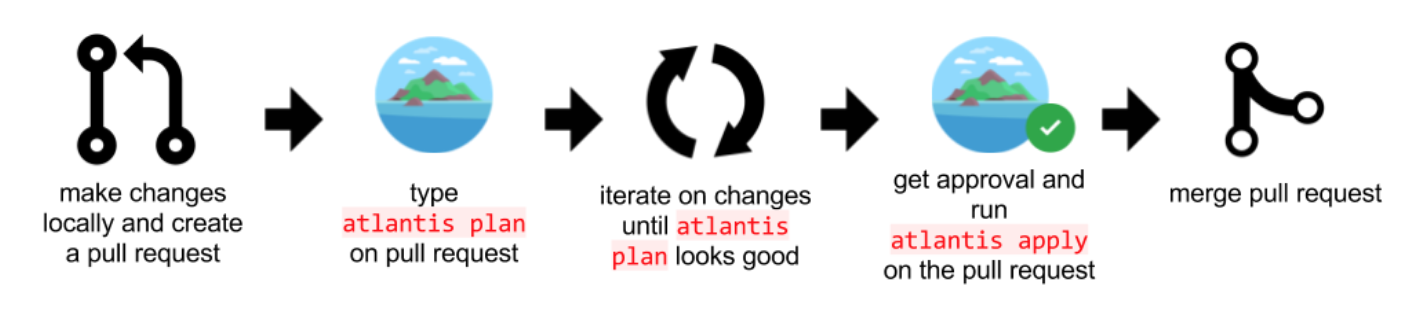
자 코드는 준비 됐습니다. 준비된 코드들을 실제 환경에 반영하기 위해서는 보통 terraform plan & apply 라는 커맨드를 사용합니다. plan 을 통해 dry-run된 결과를 확인하고 이후 apply를 통해 반영을 하게 됩니다.
하지만 저희는 이와 같은 단계들을 로컬 환경에서 하지 않습니다.
첫 번째, 코드를 준비할 repository에 PR(Pull request)을 만듭니다.
두 번째, Atlantis라는 pull request automation tool을 이용하여 atlantis plan 커맨드를 통해 dry-run된 결과를 받고 리뷰를 받습니다.
세 번째, 승인이 나면 atlantis apply 커맨드를 통해 실제 리소스를 반영합니다. 이 때 두 가지 이벤트가 발생합니다.
- tfstate 라는 적용한 리소스들의 목록이 담긴 json파일을 s3에 올립니다.
- 코드로 명시했던 리소스들을 만들어냅니다.
네 번째, 모두 반영이 되면 PR은 머지가 됩니다.
Infra Testing & Provisioning
하나의 격리된 환경을 여러 횟수로 만들기 위해서 재사용 가능한 모듈을 사용했습니다. 만약 모듈에 새로운 리소스가 추가된다고 할 때, 이를 어떻게 검증해야할까요?
Development/Staging/Production 크게 세 단계로 나누어 검증하고 배포하고 있습니다. 우선 Development 환경에서 새로운 리소스가 추가된 모듈 버전을 업그레이드를 하고 적용합니다. 이 때 리소스 변화가 무엇인지 Production 까지 갔을 때 큰 변화는 없는지 철저히 확인합니다. Production 환경에 새로운 모듈 버전을 적용했을 때 생기는 변화를 최소화 해야 하기 때문입니다.
Development 환경에서 변화를 확인했다면 Staging 환경에 적용한 후 application들이 문제가 없는지 확인합니다. Staging 환경에서도 모듈 업그레이드를 하여 적용한 후 application들의 테스트 케이스들을 실행하여 Staging 환경에 문제가 없는지 확인합니다. 만약 문제가 생긴다면 문제를 캡처한 후 원래 module로 빠르게 rollback을 한 뒤 원인을 파악합니다.
Development 와 Staging 환경에서 검증이 완료가 됐다면 이후 Production 환경에 모두 전개를 합니다. 만약 문제가 생긴다면 Staging 에서 했던 것과 같이 문제를 캡처한 후 원래 module로 빠르게 rollback을 한 뒤 원인을 파악합니다.
달라진 점
Terraform을 이용하여 인프라를 관리하면서 많은 점들이 바뀌었습니다.
- 인프라와 application간의 Tightly coupled 고리를 끊어냈다.
- 인프라 생성 속도가 이전 보다 빨라졌습니다. 이전에는 히스토리 추적과 코드 생성을 위해 최소 1주일 정도의 시간이 소요됐다면 현재는 하루에 인프라 코드 준비 및 적용이 가능해졌습니다.
- 팀원들이 구두로 인프라 변경점을 알지 않고 코드만으로 추적 및 업데이트가 가능해졌습니다. 이에 따라 일의 속도가 빨라지는 긍정적인 효과를 볼 수 있었습니다.
미래의 인프라
인프라팀은 최대한 코드의 형상을 모든 격리된 환경이 같은 형상으로 맞춰지게끔 노력해야 합니다. 더불어 앞서 말했던 “코드가 우선이다” 라는 생각을 가지고 코드를 우선적으로 반영하여 인프라에 적용할 것입니다. 하나의 격리된 환경이 아니라 다수의 격리된 환경을 다루고 있기 때문에 이를 위해 코드의 업데이트를 항상 적용할 수 있도록 자동화할 수 있는 방법을 마련하고자 합니다.
또한 이번 블로그에서는 소개를 하지 못했지만 각 모듈은 테스트 코드를 통과해야 릴리즈 버전을 만들 수 있게됩니다. 모든 모듈에 대해서 테스트 코드를 만들어서 다양한 환경과 외부의 변화에 유연하게 대처할 수 있도록 할 것입니다.










