

Human evaluation matters just as much as automated testing
ChatGPT really came to spark when it was trained on people’s preferences on answers (RLHF). It got good because humans told it what good looked like.
As this tweet put it, “All humans will essentially be doing in the future is RLHF to modern AI systems.”

Prompts can only take you so far. You have to watch the outputs, react to them, and give feedback.
When you say you want a “kind, succinct” AI agent, you don’t really know what that means until you see its answers. And usually, the first answers are wrong. That’s the point. You adjust, refine, argue over what kind really means. Quality comes from the back-and-forth.
Right now, everyone’s obsessed with automating AI testing. And yes, it matters. Automation is the first and second pass. But it can’t be the final word. The real judges are your team, the CX team, PR team, ops team, and ultimately, your customers.
It may feel counterintuitive, but this “plumbing” work of labeling, grading, and reusing outputs is the most important part of tuning an AI customer service agent. It’s also the part few people talk about.
The payoff is compounding. Once you start accumulating this data, it never loses value. A labeled conversation today can still be useful tomorrow, next month, or next year. You can re-run the same scenario, regenerate the AI’s response, and apply the same grading criteria again. The more data you collect, the stronger the improvement loop becomes.
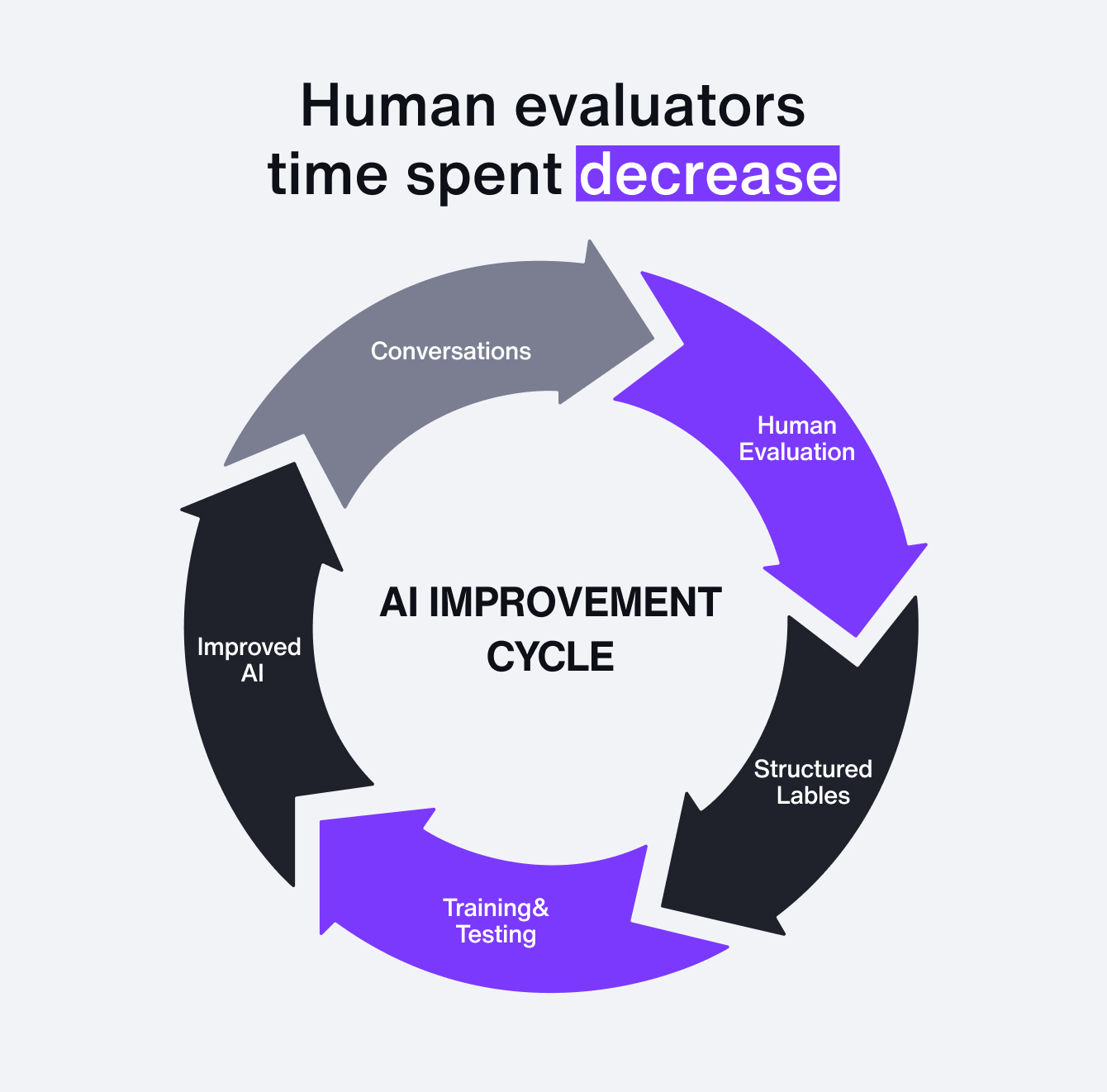
And here’s the unexpected benefit: the process forces alignment. Teams that once worked with tacit, unspoken rules now have to agree on what “good” really means, not just for today, but for how they’ll support customers in the future. Done right, AI doesn’t just automate service; it codifies and strengthens the processes behind it.
All of this points to a bigger truth: QA itself has changed. In the Agentic AI era, it looks nothing like traditional QA.
The role of QA has changed in the agentic era
Traditional QA was binary. Input → fixed output → pass/fail. You knew the expected result, and QA acted as a gatekeeper of correctness.
Agentic AI is non-deterministic. The same input can lead to multiple valid outputs. What matters isn’t just correctness. It’s tone, compliance, reasoning, and whether the answer actually solves the problem.
That changes everything:
It transforms QA from binary pass/fail into nuanced rubrics: tone, reasoning, compliance, and empathy.
It expands ownership from a single QA team into a shared responsibility across CX, PR, ops, BPOs, and even customers.
It shifts the goal from being a gatekeeper at the end to becoming the engine at the beginning, labeling, grading, and fueling a flywheel of continuous improvement.
All of this isn’t theory for us, we built it into Sendbird AI agent.
Human-as-AI-evaluator
Human-as-AI-evaluator extends Sendbird’s Trust OS capability with a new way to bring human oversight into AI performance. Instead of QA being a final spot-check, it becomes a continuous system of review, grading, and improvement. It turns subjective human judgment into structured, reusable training data.
You can assign evaluators by role, language, or function from compliance officers to frontline agents. They review conversations against configurable criteria like tone, empathy, clarity, compliance, or reasoning. And everything runs through an evaluator console that centralizes AI-handled conversations in one place, with streamlined tools (shortcuts, interactive views, permissions) to make high-volume evaluation fast, consistent, and less manual.
Automated testing keeps your AI agent on the rails. Humans as AI evaluators teach it how to drive with your people in the driver’s seat.
From evaluators to commanders
Human-as-AI-Evaluator is just the beginning. Evaluation teaches AI what good looks like. But that’s only the first step. The next phase is Human-as-AI-Commander.
Evaluators grade conversations.
Commanders steer them.
Instead of passively checking outputs, humans move to the center of orchestration. They can proactively coach the AI in real time and even take over the conversation when appropriate. Support agents gain the ability to redirect conversations, approve AI-initiated actions, intervene directly, and return the reins to AI without breaking continuity.
AI oversight isn’t about choosing between humans or AI. We believe it's about designing the systems where each makes the other stronger.