
Establishing Datawarehouse Governance with GCP (feat. BigQuery)


Background of Introducing BigQuery
Before diving into the main content, I would like to briefly share the background that led to the establishment of Datawarehouse. Previously, Sendbird analyzed data and operated the dashboard by linking Looker(BI solution) with PostgreSQL data mart created using processed product data and various data sources(Dashboard, Salesforce, Marketo, Greenhouse, etc.). Also, we were using AWS Athena to query and use the log data. However, this structure had the following issues.
- It’s not easy to query various data such as log/DB data in one place.
- We cannot join the log data and refined data to analyze them together.
- It takes too much time to query a large data size.
To address these issues, we needed storage to store and process everything from raw data in PB units to processed data up to the MB level. After carrying out POC on various products, we settled on building the Datawarehouse with BigQuery. Since it’s not easy to switch once a Datawarehouse solution is chosen, we took multiple factors into account and reviewed them thoroughly until the decision was made. I’ll also show you the steps Sendbird took when choosing a Datawarehouse solution if I have the chance. (Stay tuned!)
Introduction
As a lot of you already know, we need to consider many things to build a Datawarehouse using BigQuery.

[The approximate diagram of Sendbird BigQuery]
The main elements are as follows.
- Project structure
- Security
- IAM
- Audit
- VPC
- Monitoring
- Performance
- Cost(Slot usage)
- Performance
- Table structure
- Partitioning & Clustering
- Table Schema Management
- Resource Management
- Terraform
- Python
In this post, I’ll cover the project structure, security, and monitoring first. Let’s take a close look at how Sendbird built the items above!

Virgin Mobile UAE improved their CSAT with Sendbird Desk.
Project Structure
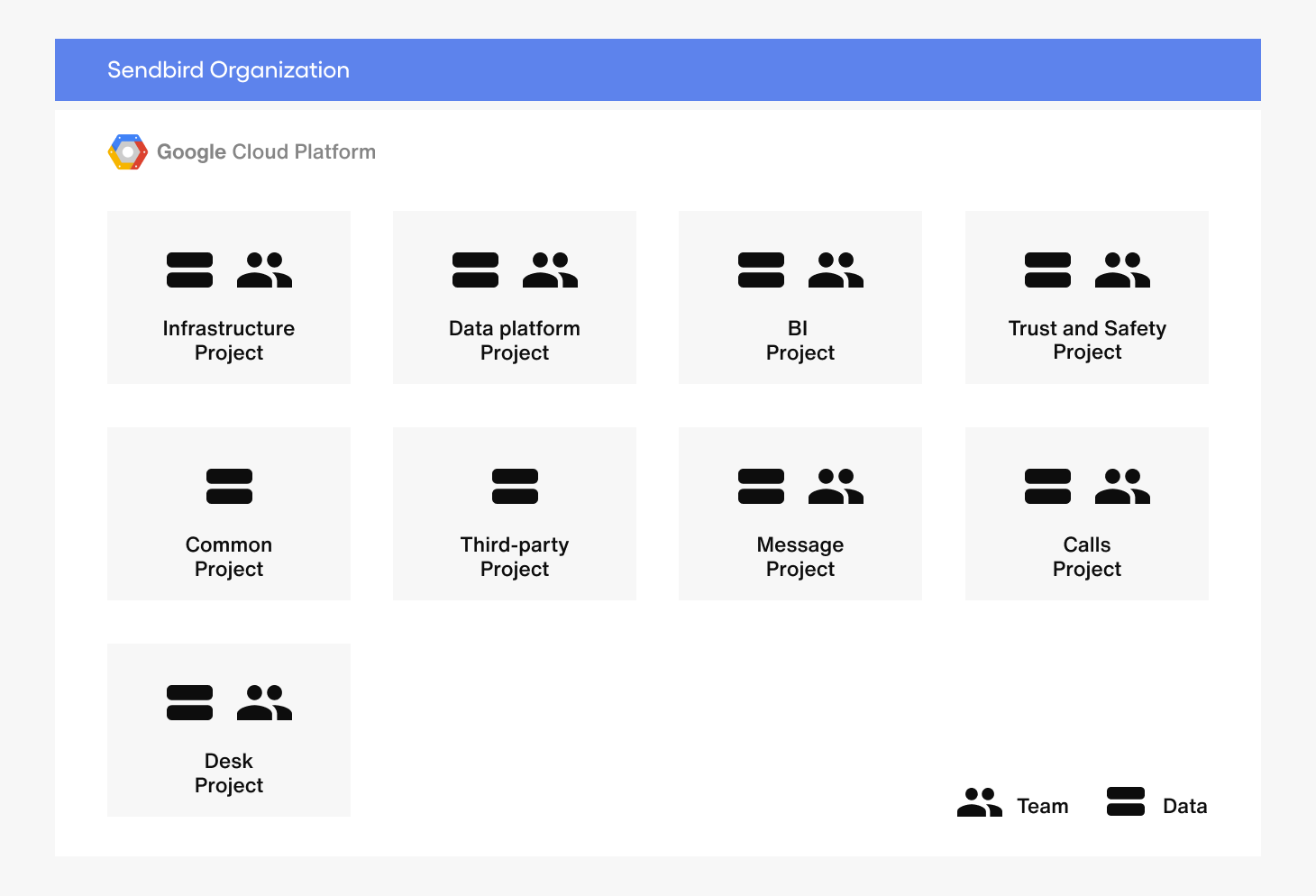
‘Project’ is an integral unit (similar in concept to ‘account’ in AWS) in GCP. It’s particularly important in BigQuery since we can distribute data access per team by project unit and assign separate slots.
We categorized the ‘project’ unit by two criteria.
- By the nature of the data
- By team
The rationale for categorizing the data by these criteria is as follows.
First, we categorized ‘Projects’ by data to design so that each team can access only the necessary ones. And the reason for classifying it by team is to enable each team’s data-driven decision-making and manage resources by distributing slots for each team.
For example, given the premise that the projects were categorized as above, we can think of the following user scenario.
Let’s assume Jordan from the BI team wants to use the message volume of customers and the AWS cost used to serve them in order to find a correlation between the two. Then, he can access and import data from Message Project (contains message data) and Third-party Project (contains AWS resource data), respectively, and create a new dataset by combining them in BI Project. Likewise, each team can create an environment where they can analyze and import data from other accessible Projects, thereby preserving the original data. For example, only the Messaging team will be able to write in the Message Project.
Our utmost priority was to design the ‘Projects’ so that each employee can readily search and access the data they need and allow the admin to control them with flexibility as the company grows with more teams and products. We reflected Taeyeon’s (manager of the Data Platform team) opinion and experience with the Datawarehouse at Amazon. We are very grateful for her input. 🙂
Security
Next, I’ll cover security. Security is one of the most critical factors for a B2B software. When introducing new tech or solution at Sendbird, we first review if it’s safe enough from a security perspective and how we can establish essential items such as access control and logging.
IAM
As for IAM Resource, we applied the three following items.
- Since we use G Suite’s Group to grant authorization, there is no need for additional management when a team member joins or leaves the company.
- In production, we configured it so that individual users have viewing permission and actual data can only be written with the application’s service account.
- Service accounts are separate in each application.
- Service account of each team’s application
- SQL Runner Service account of Looker
- Dashboard Service account of Looker
- Monitoring Application Service account
- ETC
Audit
Auditing is essential for compliance, such as ISO27001 and SOC2.
For this, we made two considerations.
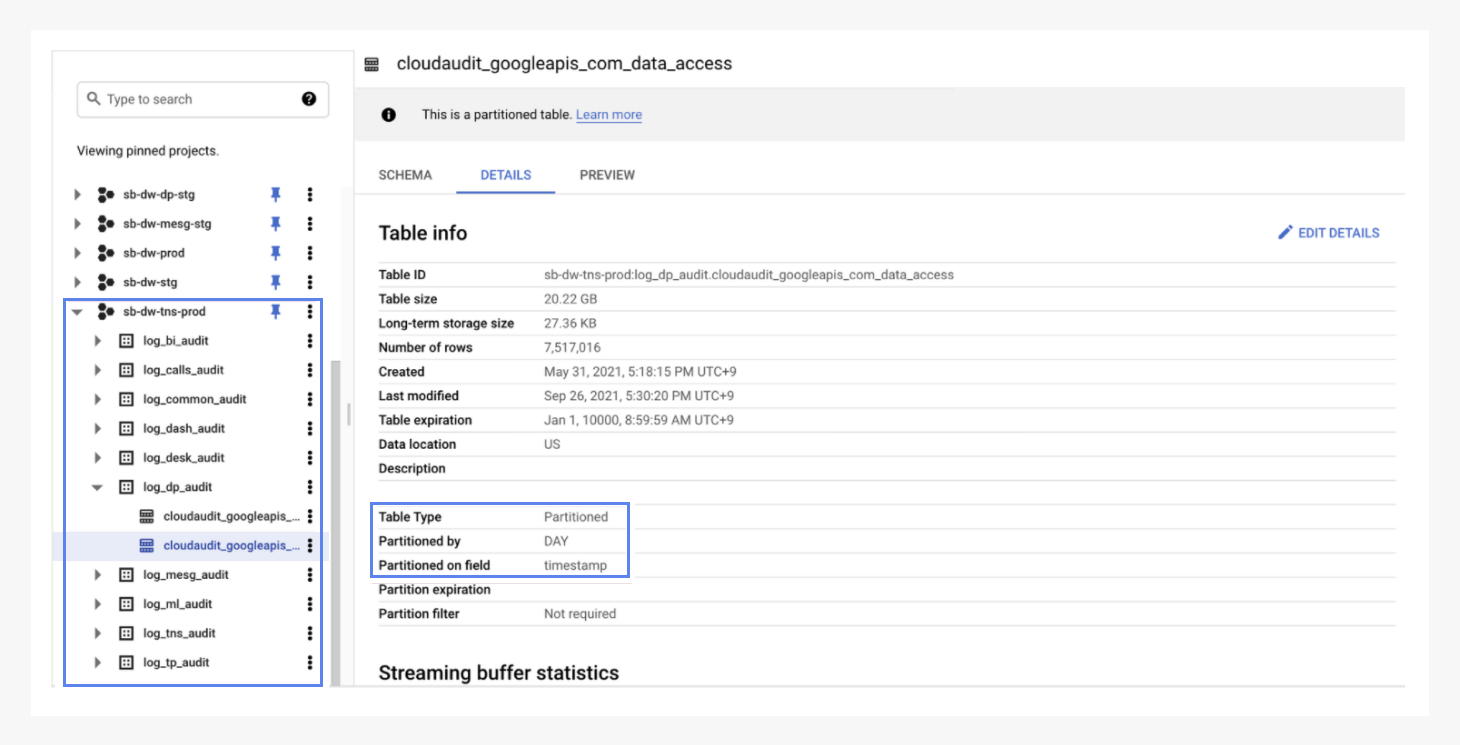
1. Partitioning for data retention for cost management
Logs can accumulate massive data in a flash. This will lead to increases in various expenses. From the initial stages, we configured the retention in accordance with Sendbird’s internal guidelines and set the partition to ‘daily’ for easier management.
2. Establish an environment where the T&S team can view the logs by themselves
At Sendbird, the log of each project is saved in the project of the T&S team through the sink of the GCP Log Router. With the proper queries, the T&S team can directly check the logs at any given time.
VPC
Lastly, I’ll cover VPC, which is the last part of Security.
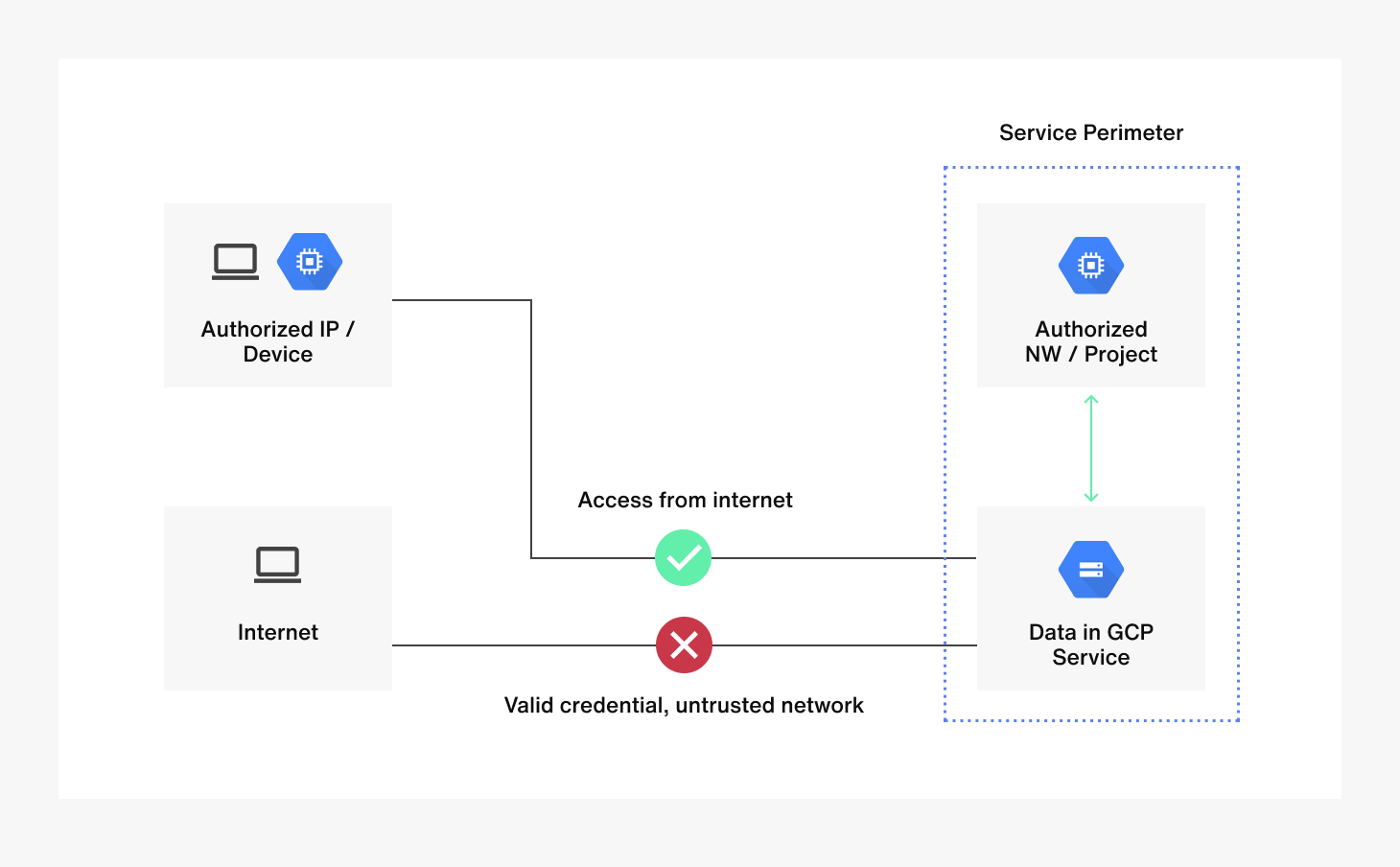
Physical security is critical since secrets such as ID/PW can be exposed anytime. Sendbird applied the ingress rule through GCP’s Access Context Manager and VPC Service Controls to enable access only from an in-house VPN or Application IPs that require data access (Airflow’s NAT Gateway IP, etc.). The above is the Terraform sample code that configured staging.
If you want details on the VPC Service control, please refer to the documentation below.
https://cloud.google.com/vpc-s...
In short, Sendbird protects data by establishing Project structures, auditing, and VPC, etc.
Monitoring
Now I’d like to discuss monitoring, which is the last section of chapter 1. The most crucial factor for a stable operation is monitoring. A project is never truly complete unless monitoring is properly established.
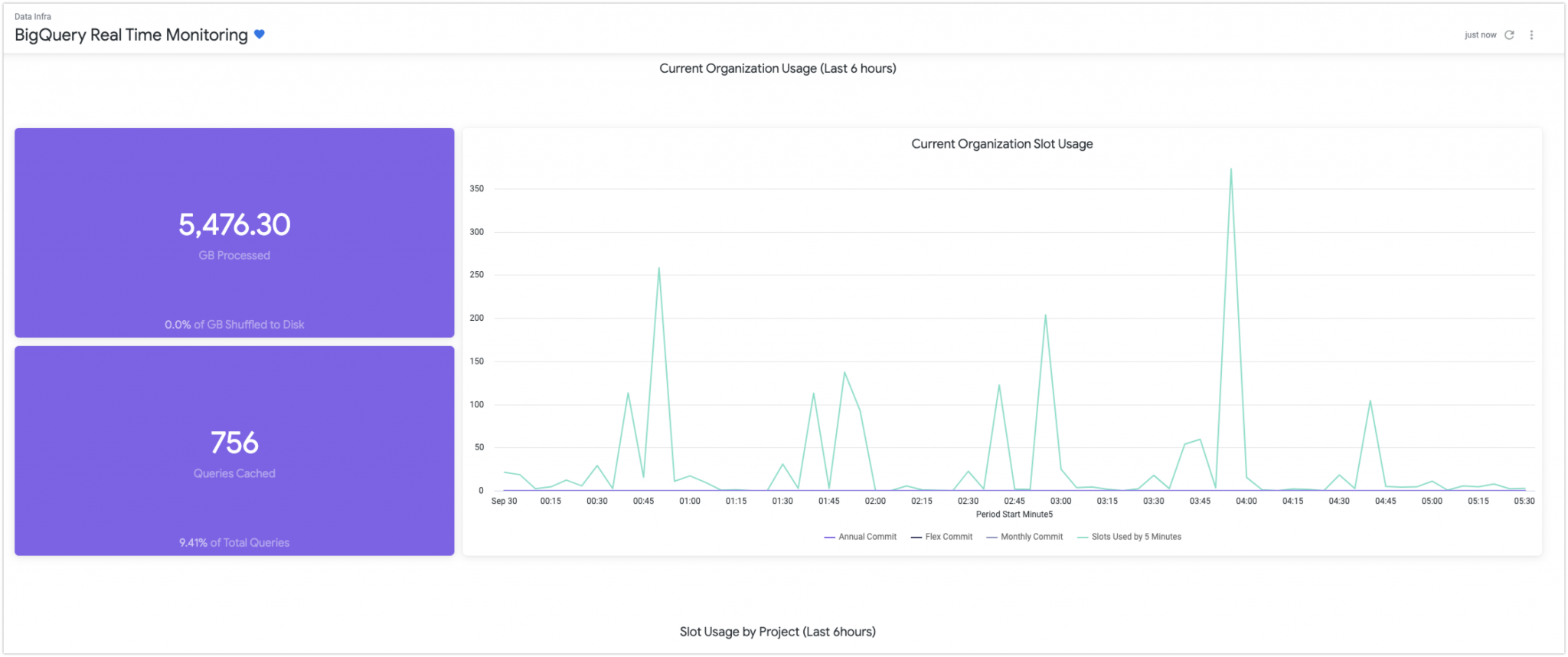
We focused on performance and cost as we established a monitoring system.
- Whether efficient queries are being used
- ex. Check if there are shuffled data in the disk and determine if there’s a larger calculation than the purchased slot volume
- Slot monitoring to estimate slot demand
- ex. Able to save cost by making on-demand purchases through real-time slot monitoring.
- Check necessary resources for each team by utilizing slot usage per project
Dashboard and alert are most important when it comes to monitoring. Since Sendbird was already using Looker, a BI service, we used it to build our dashboard.
Now I’ll share which data we used to build the dashboard. BigQuery’s Information_schema provides the metadata below.
- dataset metadata
- job metadata
- job timeline metadata
You can see further details of the schema here in the link.
https://cloud.google.com/bigquery/docs/information-schema-intro
In order to monitor the usage in almost real-time, Sendbird built a dashboard using the open-source project ‘bq_info_schema_block’ that had implemented BigQuery’s information_schema into LookML. They have various useful pre-built dashboards, so you can use them right away and customize them according to your needs.
https://github.com/looker/bq_info_schema_block
To wrap things up, we have discussed the following requirements for establishing Datawarehouse governance with BigQuery.
- Project Structure
- Security
- Monitoring
If you have any questions, please leave a comment or email anytime. Also, if you happen to be interested in this topic, maybe we could build a better Datawarehouse together at Sendbird!
See you in the second chapter!










