
SB-OSC: Sendbird Online Schema Change


Introduction
Online schema change is an essential process when managing services using MySQL databases. Optimizing dating structure, adding new features, performance improvement, or enhancing data security often involves schema change on related tables. However, performing such changes inevitably leads to service interruptions, which can degrade user experience and significantly impact business. Therefore, the method of changing the database schema online, without downtime, is very important.
Existing online schema change tools, especially gh-ost, fb-osc, and pt-osc, operate in single-thread and do not track their progress outside the process scope. These tools can be terminated or stopped for various reasons (e.g., process errors, table lock contention, OS kill due to load), and in such cases, the migration process cannot be resumed. To restart the interrupted work from the beginning, it's necessary to clean up the residual tables, and for pt-osc and fb-osc, it's also required to remove the remaining triggers.
This problem becomes more severe for large tables. Online schema change tasks for tables containing hundreds of gigabytes to terabytes of data can extend from weeks to months. This extended operation time will likely lead to tech debt.
Against this background, our team, based on our experience, developed a new MySQL online schema change tool based on multithreading, SB-OSC. SB-OSC overcomes the temporal limitations of existing tools through multithreading, significantly shortening the schema change process for large tables to just a few days. Moreover, SB-OSC offers a powerful feature that allows work to be perfectly resumed from the point of interruption as long as the binlog is alive, innovatively improving tasks that previously took months to complete. This has significant implications as it makes schema changes in large OLTP tables feasible which were nearly impossible before.
This blog will provide a detailed introduction to the design philosophy and implementation methods of SB-OSC, offering a deep understanding of the challenges and solutions for schema changes in large tables.
Methodology
The design of SB-OSC is based on two key philosophies. First, it ensures the ability to resume work from the point of interruption. To achieve this, SB-OSC divides the work into clearly defined stages and records the progress of each stage in the database. Additionally, it stores the minimum necessary data in the database to recover the progress of each stage, allowing work to be resumed from the point of interruption. This significantly reduces the complexity and risks of long operation times for schema change on large tables.
Second, SB-OSC utilizes multithreading to optimize performance. For this purpose, SB-OSC separates the ‘Bulk Import’ stage, which involves copying the original data, and the ‘Apply DML Event’ stage. The ‘Apply DML Event’ stage applies DML events to the new table not by replicating the original statements but by copying the data based on the primary key (PK). In other words, it synchronizes the final state of the original table with the new table instead of replaying what happened on the original table. This design allows SB-OSC to handle DML events regardless of their chronological order, which offers significant advantages in implementing multithreading.
SB-OSC also applied multithreading when processing binlogs, so that it can successfully perform migrations on tables with gigabytes of binlogs being created every minute. SB-OSC uses file based multithreading, operating in a single-thread under normal circumstances but capable of processing multiple binlog files simultaneously as needed. This enables near real-time binlog processing even for tables experiencing thousands of DML events per second, where the speed of single-threaded binlog processing cannot keep up with the accumulation of changes.
These design philosophies enable SB-OSC to operate more powerfully and flexibly in large database environments. We will now take a closer look at how these philosophies have been implemented in each stage.
0. Initialization
The initialization stage is where various tables and Redis keys necessary for the operation of SB-OSC are defined, creating basis for self-heal when work is interrupted or when there are problems with the data. SB-OSC uses two types of storage: DB and Redis. A separate logical database is created within the database undergoing schema changes to store various data for recovery, while Redis stores information that can be quickly accessed by the various processes of SB-OSC. The database tables store data that must not be lost in order to resume work, and Redis stores data that is commonly used and frequently accessed by various components of SB-OSC.
1. Binlog Processing
The binlog processing stage parses binlogs to identify events where DML operations occurred, and it has two main characteristics.
First, it collects DML events and stores them in three separate tables for INSERT, UPDATE, and DELETE. It doesn't store the specific details of the DML events but only saves the PK values where INSERT, UPDATE, and DELETE occurred, along with the timestamp of the occurrence, in separate tables. There are several reasons for this.
By storing events up to the current point, it enables tasks to be resumed from the point of interruption. Upon a certain interval or when a certain number of INSERT, UPDATE, and DELETE events are parsed from the binlog the events are flushed to the database, and writes the current binlog file, position, and the last event timestamp to the table. On restart, binlog processing will be resumed from the last recorded file and position stored in the table. Also, recording the events and position in the tables ensures that all parsed events from the binlog are saved in the database
Also, when saving PKs to database duplicate updates on the same PK can be removed by using INSERT INTO ON DUPLICATE KEY. Instead of replaying the DML statement, it copies the record corresponding to the PK from the original source. Therefore, if a duplicate update on the same PK occurs, only one final update is needed, allowing it to effectively follow updates that occurred in the original table.
Lastly, it allows SB-OSC to reuse event PKs multiple times during the entire process. This is particularly useful when applying DML events to the new table, where several data validations take place. By storing the events in the database, it enables repeated data validations for the corresponding PKs.
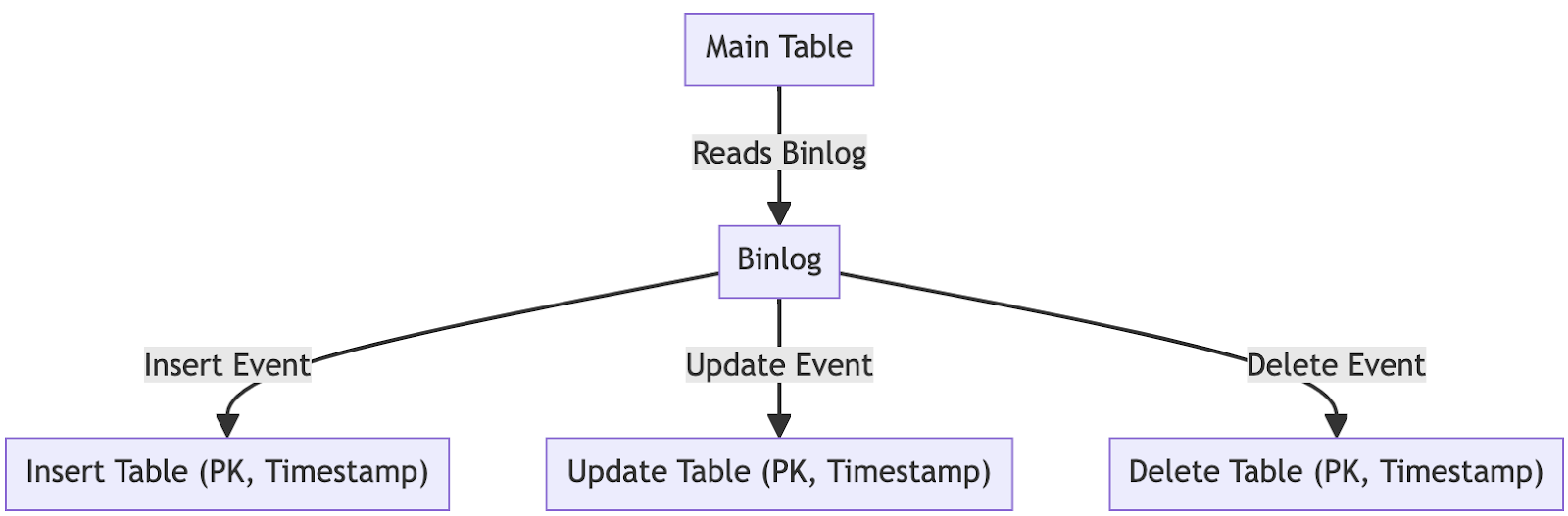
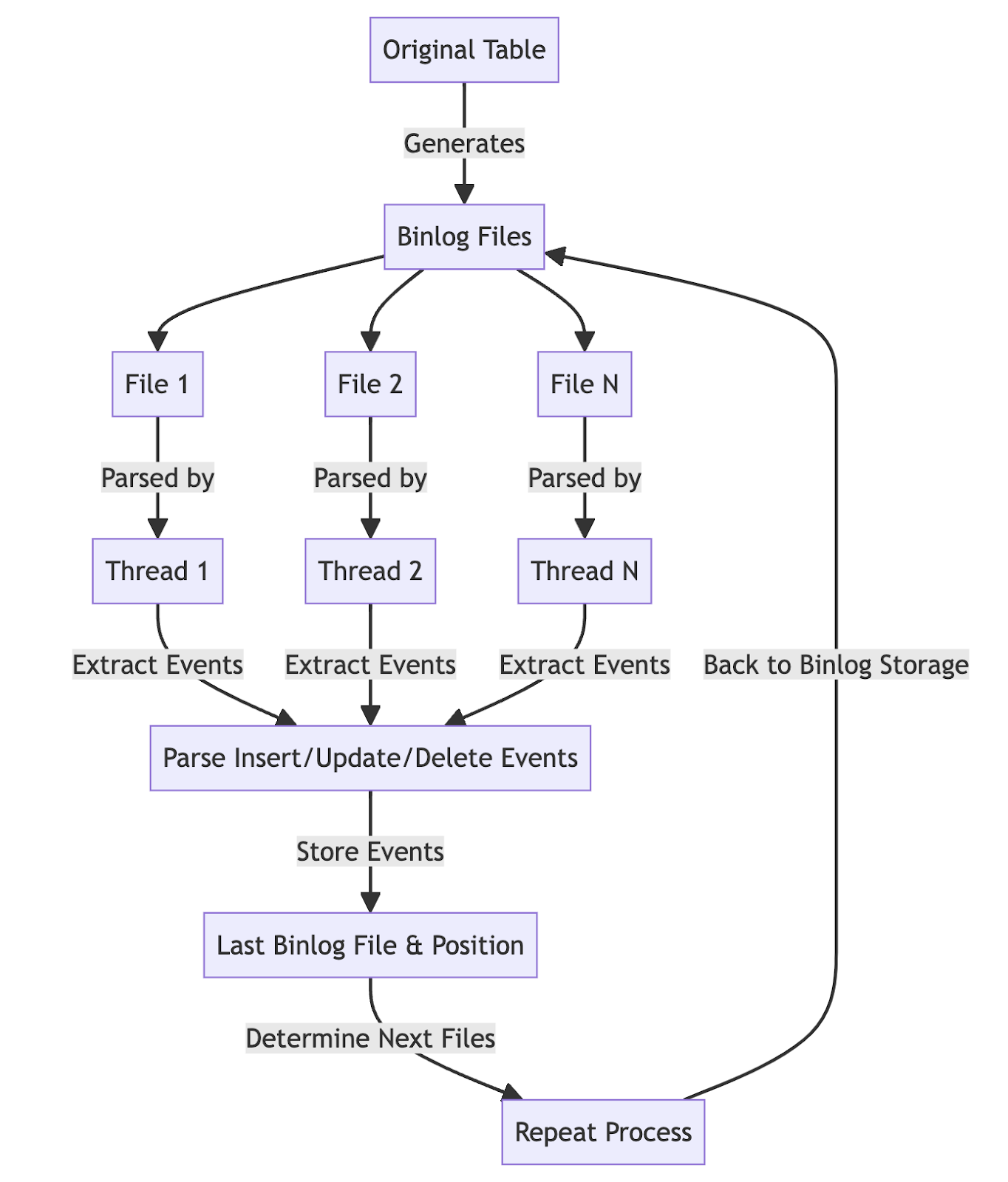
The second characteristic is the application of multithreading to process multiple binlog files simultaneously. When a large volume of DML occurs in the database, single thread binlog processing couldn’t keep up with the speed of binlog creation.
SB-OSC addressed this issue by bundling a few binlog files in order and processing them simultaneously, handling all discovered events at once. It operates in a single thread under normal circumstances. If more than two files have been added after the last read binlog file, SB-OSC processes up to four of these files in parallel, then eliminates duplicates for the same PK before saving them all in the database, and records the most recently created binlog file and the last read position in the database. This approach enabled near real-time binlog processing, even for tables where thousands of DMLs occur per second.
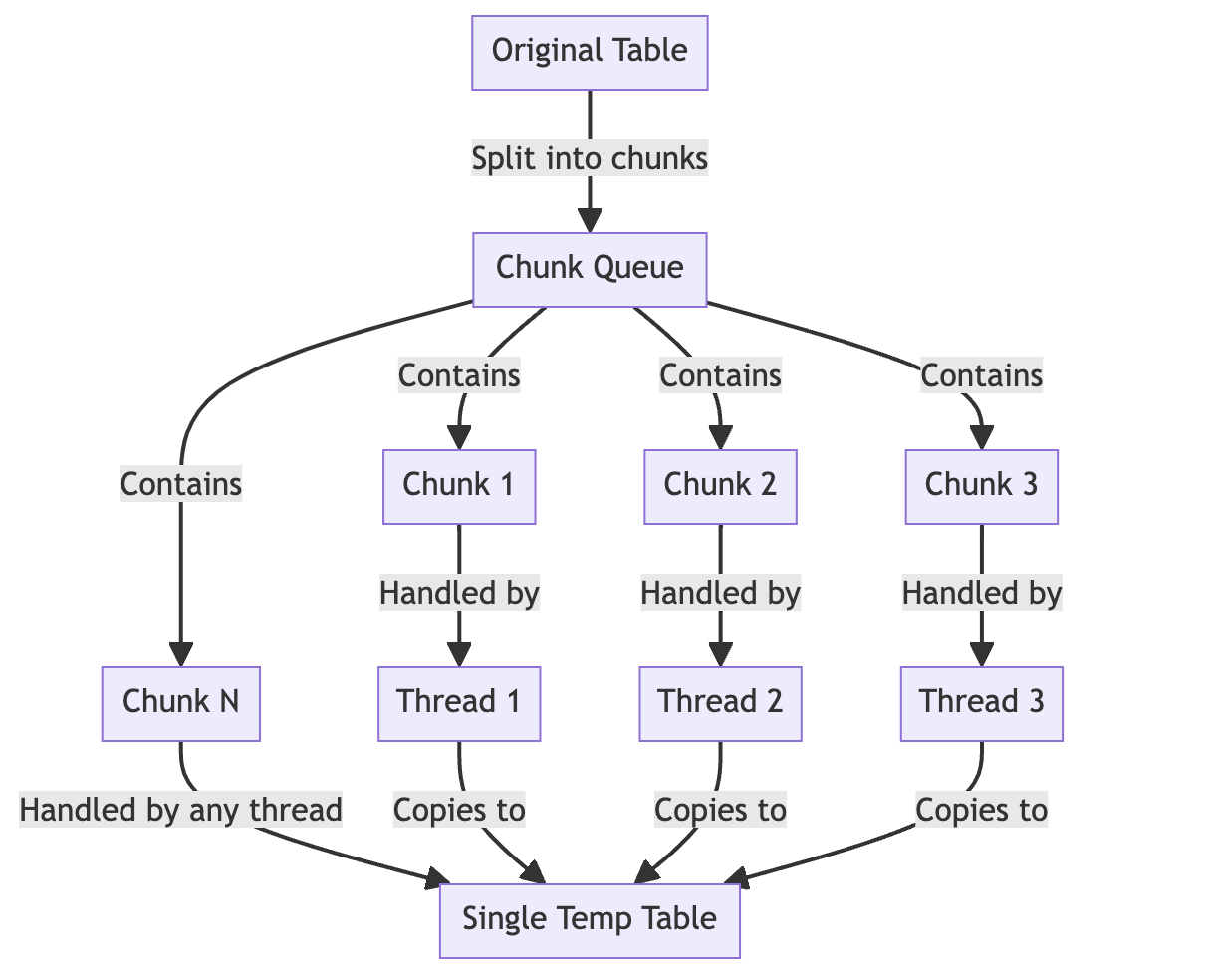
2. Bulk Import
In the bulk import stage, it copies the original table to a new table by dividing the table into multiple chunks based on the PK value and then copying several chunks simultaneously using multithreading. This is a crucial step in implementing SB-OSC's multithreading.
Each chunk is handled by a single thread, and each thread performs the INSERT INTO SELECT query in small batch units within the range of the chunk. Since the PKs inserted to the original table after starting the migration process are all stored in a separate table, the bulk import stage only copies data up to the max id of the original table before migration has started. Records that are inserted or updated after starting migration will be processed in the DML event application stage.
Existing online schema change tools replicate the table while using triggers or binlog to reflect DML events occurring on the new table in real-time. Although this simplifies the process, it can hinder the overall speed in situations with a large volume of DML events. Inserts occurring in the same PK range as DML events cause lock contention, increasing latency. Additionally, as the schema change process extends, updates on records copied early on occur multiple times, leading to increasingly higher accumulated load over time.
In SB-OSC, this issue was resolved by separating the bulk import and DML event application stages. During the bulk import stage, it's possible to copy a large volume of records quickly with multithreading without considering DML events, since it involves copying the PKs stored up to that point. During the DML event stage, it efficiently reflects DML events by eliminating all duplicated PKs that occurred during the bulk import process.
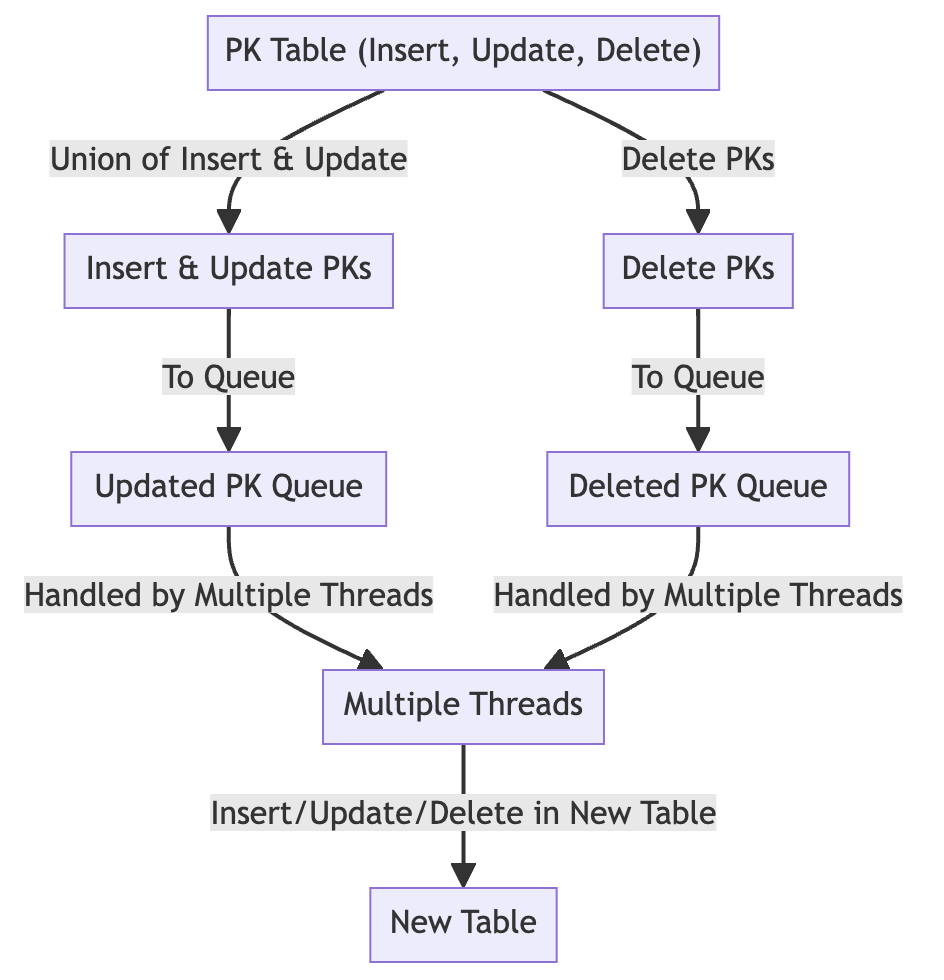
3. Appy DML Events
After the bulk import is completed, DML events stored through binlog processing are applied to the new table. Events are read in timestamp order from the table where INSERT, UPDATE, DELETE are stored and applied to the new table accordingly. As explained above, instead of replicating the executed statements, it copies the data from the original table that has the corresponding PK values directly, allowing for the application of multithreading ignoring the actual order of DMLs.
Additionally, beyond optimizing updates of duplicate PKs with INSERT INTO UPDATE ON DUPLICATE KEY, further optimization is conducted by calculating the union of INSERT and UPDATE PKs and the difference from DELETE PKs. Since INSERT and UPDATE can be processed with the same query using INSERT INTO UPDATE ON DUPLICATE KEY, a union is performed. For DELETE if they are processed after INSERT and UPDATE there's no need to reapply it, hence the difference is calculated.
Through these optimization, SB-OSC was able to minimize the amount of DML to be applied and significantly reduce the overall migration time.
4. Swap Tables
After all the above processes are completed and there are no more DML events to apply, the names of the newly created table and the original table are swapped. The table swap involves temporarily changing the name of the original table to block traffic, asynchronously applying DML events that arrive during the brief name-changing period to the new table, and then changing the name of the new table to that of the original table.
During the table swap, binlog processing continues without pause. If a failure occurs due to DML events not being applied during the swap, the original table's name, which was temporarily changed, is restored, ensuring normal service operation.
If the process restarts while the original table's name is temporarily changed, it first checks for the existence of a table with the same name as the original in information_schema.TABLES. If there isn't one, it restores the temporarily changed name of the original table to normalize the service before attempting the table swap again.
Sustainability
It is common to consider the use of multithreading to improve speed and efficiency during schema changes as a trade-off with data consistency and process stability, often leading to choosing the latter. However, SB-OSC is designed and engineered to break through this trade-off, incorporating both features by implementing various safety mechanisms and data integrity check logic.
1. Binlog Processing
Since SB-OSC continuously validates whether DML events are well applied in the latter part of the process, the binlog processing stage must ensure that PK values where DML events have occurred are not missed and are accurately recorded in the database. To guarantee this, events are saved to the database only after all files currently being processed are done. If all events have been successfully saved, it saves the last file and position read up to that point. When the event parsing process restarts, it resumes from the last file and position saved in the database, ensuring that if an error occurs while storing a DML event, it can resume from the last successfully saved position without missing any events, thereby guaranteeing that all are stored in the database. Additionally, to verify that all existing binlogs have been processed, SB-OSC continuously updates the time it reached the end of the existing binlog files, which will be used to check if there are any binlogs left to process during the table swap stage.
2. Bulk Import
During the bulk import stage, chunks are managed in three ways: their ids are stored in a Redis Set, chunks are managed in a LIFO manner using a Redis List as a Chunk Stack, and finally, detailed information about each chunk is stored in a database table.
Threads executing INSERT queries use chunks pulled from the Chunk Stack. Once a chunk is selected, its status is updated to IN_PROGRESS in a Redis Hash specific to each chunk. Each thread inserts small batches of data with a single query, and with each successful query execution, the last_inserted_pk value in the chunk's Redis Hash is updated. Because last_inserted_pk is updated only if the batch is successfully inserted, it guarantees that insertion up to the last_inserted_pk has been completed.
If an error occurs while performing an INSERT query and updating the Redis Hash, preventing last_inserted_pk from being updated, another thread processing the same chunk later may encounter a duplicate key error. In case of a duplicate key error, the INSERT query for the same batch is retried with an UPDATE ON DUPLICATE KEY clause added to the query. Since only the final state needs to match, re-fetching and updating from the original source wouldn’t cause problem. If processing is interrupted due to any other error, the try-except block returns the chunk back to the Chunk Stack and retrieves a new chunk. Once the processing of a chunk is completed successfully, its status is updated to DONE, and it is not returned to the Stack.
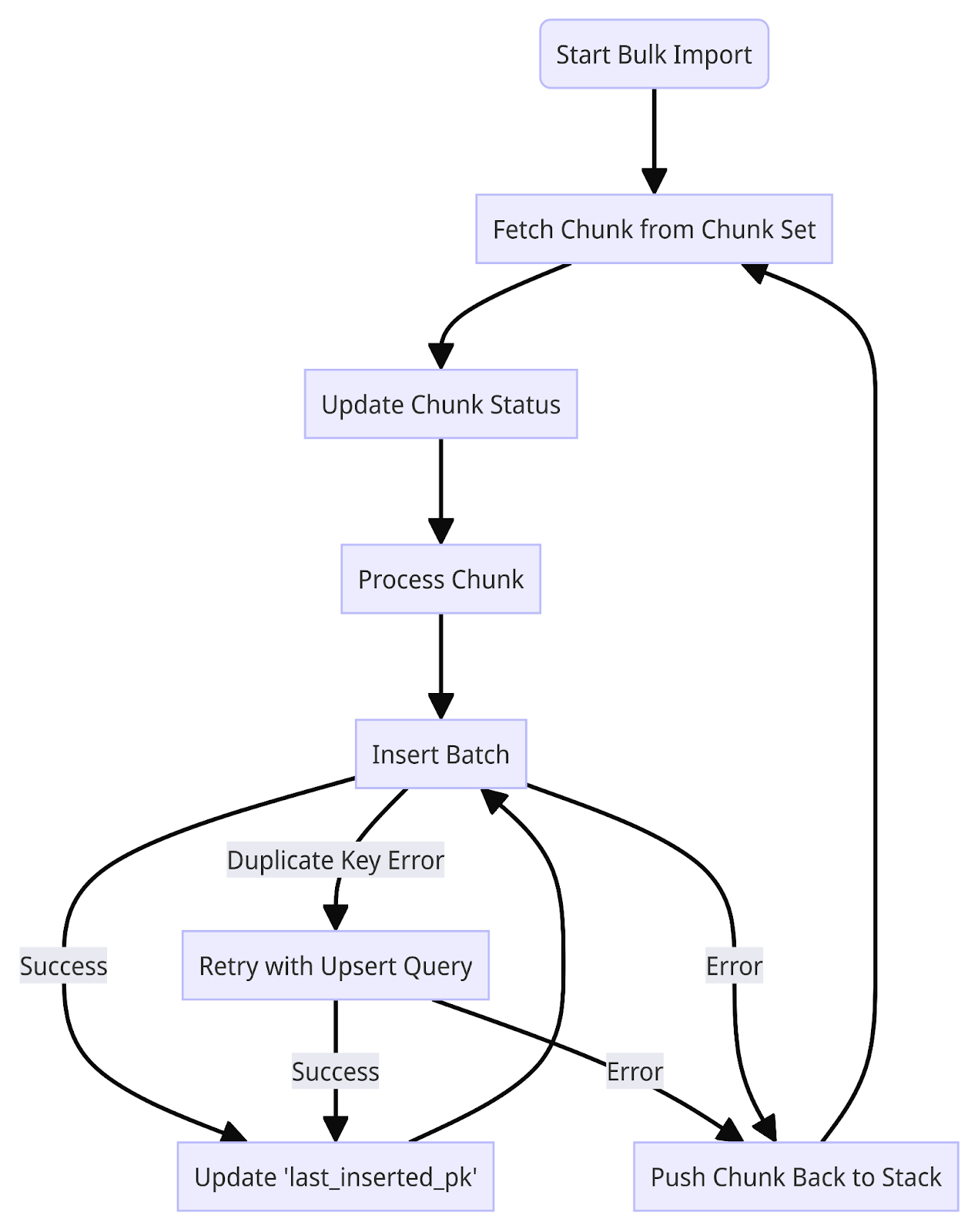
During the validation process, the first step is to verify whether the number of chunks in the Chunk Set matches the initially created quantity. If there is a missing chunk, it queries the database to retrieve and restore the information. Next, it checks if all chunks are in the DONE state and whether the end PK value of each chunk matches the last_inserted_pk. If a chunk is in the IN_PROGRESS state or the last_inserted_pk is smaller than the end PK, the chunk is added back to the Chun k Stack to resume processing from the last_inserted_pk.
After the basic validation of chunks is completed, a SELECT query is used to ensure all data has been correctly copied to the database. A multi-threaded query that performs a LEFT JOIN between the original and new tables by dividing the PK range is used to check for any PKs in the original table that were not copied over the entire range.

In addition to data validation, SB-OSC has a self monitoring system to ensure the process does not overly burden the database. Sendbird operates SB-OSC within an AWS environment, and SB-OSC includes a process that independently monitors the CloudWatch metrics of the running RDS cluster.
Using this process, when metrics such as CPU, WriteLatency, and DML latency spike, there is a feature that can reduce the number of threads or batch sizes to match the database load or even temporarily stopping the process by setting these parameters to 0. This ensures stable operation even when facing production traffic.
3. Apply DML Events
In the DML event application stage, it checks if all events that have occurred after the start of the migration process are correctly applied to the new table. Since the bulk import validation stage ensures that all records have been successfully copied during the bulk import stage, and all PK values where DML events have occurred are stored in the database through binlog processing, checking if all INSERT, UPDATE, DELETE are applied correctly only on the DML event PKs will be an efficient and sufficient method to check data consistency instead of comparing all records in real-time which will cause significant read load on the database.
For INSERT, it checks if there are any records in the original table that are missing in the new table. For UPDATE, it compares the values of all columns of records with the same PK in both the original and new tables. For DELETE, it checks if records with the specified PKs still exist in the new table. In all cases, the original state is checked first; if an INSERT was made but the record is not found in the original, it is considered deleted and not reflected in the new table. Conversely, if a DELETE was performed but the record still exists in the original, it is considered as re-inserted and not deleted.
If there are PKs with mismatching data, these PKs are stored in a separate table, and attempts to retry each insert, update, or delete are made until the data of those records matches.
This validation process is performed at two seperate intervals. One cycle involves validating from the timestamp of the last verified event to the current time, and another cycle, which can be modified by a parameter, involves validating all events from the beginning at given interval.

4. Swap Tables
The final table swap stage is attempted once all DML event consistency checks have concluded, and even the events incoming in real-time have been processed. The table swap process involves the following steps:
Once all events are applied to new table and data integrity checks are completed, the state of the original and new tables momentarily aligns. At this point, the original table's name is temporarily changed to block queries to the original table.
Then, all momentarily occurred events are processed, and data validation logic for events occurred during the swap is executed.
To ensure all binlogs have been read, it checks if the last timestamp to finish binlog processing in Redis is after the table name change period.
If all these processes are successfully completed within 3 seconds, the new table's name is changed to the original table's name. Otherwise, the original table, whose name was changed, is reverted to its original name.
During the 3 seconds while the original table's name is temporarily changed, traffic may not enter, potentially causing errors. However, this is a problem shared by existing open-source schema change tools, thus can be considered a limitation of online schema change itself.
As described, by precisely defining what is needed for consistency in each step and creating specific mechanisms to achieve this, it enables stable schema changes across various table conditions and circumstances.
Limitations
SB-OSC effectively utilizes multithreading and provides the ability to resume interrupted tasks, resulting in superior performance on large tables with large volumes of DML compared to existing online schema change tools. However, SB-OSC also has several limitations
1. Integer Primary Key
SB-OSC performs multithreading in the bulk import stage based on integer PKs. This is because batch processing and other operations are also designed around integer PKs. Consequently, tables without integer PKs cannot utilize SB-OSC.
2. Primary Key Updates
SB-OSC applies DML events by copying records from the original table based on PK. Therefore, if updates occur on the table's PK, it becomes challenging to guarantee data consistency.
3. Binlog Timestamp Resolution
SB-OSC is limited by the binlog's timestamp resolution being in seconds. While this doesn't significantly impact most scenarios due to SB-OSC's design features, it can affect the logic based on timestamps when excessive events occur within a single second.
4. Reduced Efficiency for Small Tables
For small tables, the initial table creation, chunk creation, and the multi-stage process of SB-OSC can act as overhead. This can slow down the overall speed, making SB-OSC less effective for small tables.
Performance
SB-OSC shows high performance on both binlog event processing and bulk import. To give you a general idea of SB-OSC's performance, we are including our performance test results. SB-OSC operates on AWS Aurora MySQL and EKS, requiring the following setup:
AWS Aurora MySQL cluster (v2, v3)
EKS cluster
Containerized Redis
binlog_format set to ROW
binlog-ignore-db set to sbosc (recommended)
It is composed of four components, each configured as a separate StatefulSet. The component that processes binlogs can use up to 2 vCPUs, while the remaining three pods typically consume less than 0.5 vCPU in most cases.
Following are specs of tables used for performance testing. All tables were in the same Aurora MySQL v3 cluster
Table Alias | Avg Row Length (Bytes) | Write IOPS (IOPS/m) |
A | 57 | 149 |
B | 912 | 502 |
C | 61 | 3.38 K |
D | 647 | 17.9 K |
E | 1042 | 24.4 K |
F | 86 | 151 K |
G | 1211 | 60.7 K |
Avg Row Length is avg_row_legnth column from information_schema.TABLES, and Write IOPS is average increase of count_write from performance_schema.table_io_waits_summary_by_table per minute.
Binlog Event Processing
Following are read throughput of binlog event processing on each table in read bytes per minute. By comparing read throughput to total binlog creation rate of the cluster, we can see whether SB-OSC can catch up DML events or not.
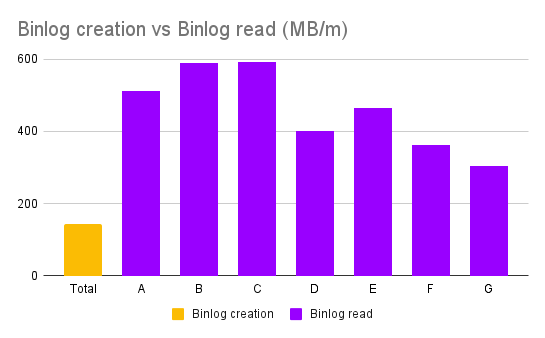
As shown in the chart above, SB-OSC can cach up DML events on table with very high write load.
Bulk Import
Bulk import test was conducted on table A with no secondary indexes, and no additional traffic. Actual performance can vary depending on the number of secondary indexes, the number of rows, column types, production traffic, etc.
Following are the results of bulk import performance based on instance types
Instance Type | Insert Rate (rows/s) | Network Throughput (Bytes/s) | Storage Throughput (Bytes/s) | CPU Utilization (%) |
r6g.2xlarge | 42.3 K | 27.2 K | 457 M | 55.0 |
r6g.4xlarge | 94.0 K | 45.9 K | 900 M | 51.9 |
r6g.8xlarge | 158 K | 72.2 K | 1.39 G | 44.6 |
Insert rate, network throughput, and storage throughput are the average values calculated from CloudWatch metrics.
Comparison with gh-ost
To compare overall performance with existing schema change tool, we’ve measured total migration time for SB-OSC and gh-ost on following conditions
Table C with ~200M rows
Aurora MySQL v3 cluster, r6g.8xlarge instance
2 secondary indexes
batch_size (chunk-size for gh-ost): 50000
(gh-ost) --allow-on-master
gh-ost was chosen for comparison since it uses binlog for DML events collection like SB-OSC.
Without Traffic
Tool | Total Migration Time | CPU Utilization (%) |
SB-OSC | 22m | 60.6 |
gh-ost | 1h 52m | 19.7 |
With Traffic
Traffic was generated only to table C during the migration. (~1.0K inserts/s, ~0.33K updates/s, ~0.33K deletes/s)
Tool | Total Migration Time | CPU Utilization (%) |
SB-OSC | 27m | 62.7 |
gh-ost | 1d+ | 27.4 |
For gh-ost, we interrupted the migration at 50% (~12h) since ETA kept increasing.
SB-OSC show higher insert throughput and is able to utilize database resources efficiently on large database instances. It shows bigger difference on tables with heavy traffic due to the optimizations on DML application stage.
Conclusion
Sendbird's DB structure is an environment that requires frequent schema changes. With over 40 databases for Chat alone, schema changes in large regions have always been a significant challenge. In this process, although we previously used pt-osc, we encountered numerous difficulties, including having to stop work several times and encountering failures while creating triggers.
The basic process of SB-OSC is actually a codification of the know-how our database engineers have gained from their extensive experience, formerly carried out manually during low traffic periods in each region over several weeks. Automating the labor-intensive work of our team members and being able to complete tasks in days that would otherwise take months signifies tremendous progress.
Using this tool, we successfully completed the largest schema changes in Sendbird for the year 2023 which involves tables with terabytes of data and multiple indexes. This couldn’t have been done without the help of SB-OSC
With many schema change tasks still pending in Sendbird's DB, we look forward to actively utilizing SB-OSC in the future and are hopeful about making structural improvements to the DB that were previously impossible due to schema change challenges.
Please refer to our source code for more detail.








