
Infrastructure management using Terraform

Introduction
Hello, I’m Eden, an Infrastructure Engineer at Sendbird.
Today I’d like to share the status of Sendbird’s infrastructure and the backstory of how we settled with Terraform as our infrastructure management tool.
Before diving in, I would like to share the current status of Sendbird’s infrastructure (hereinafter 'infrastructure') and its management.
The graph below shows the total number of EC2 Instances in use since May 2020.
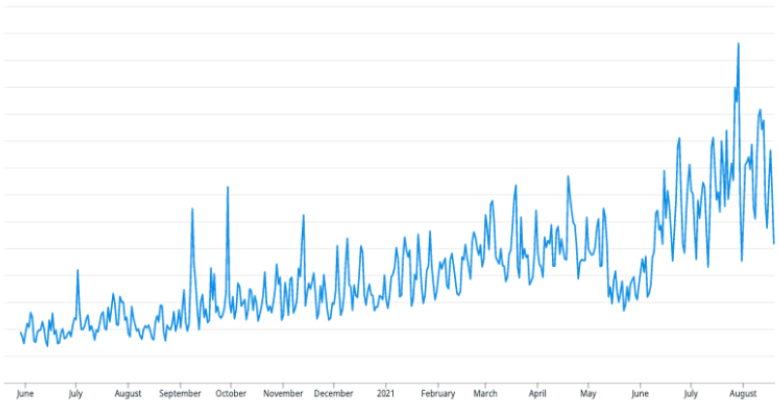
In order to safely process and manage the data of Sendbird’s customers, each customer’s infrastructure has been isolated at the network level. We were using 8 AWS regions when I first joined Sendbird, and since then, the number has increased to 11. The size of the infrastructure also increased 1.5 times and will continue to grow in the future.
The following is the list of AWS resources currently in use that I confirmed prior to an internal presentation.
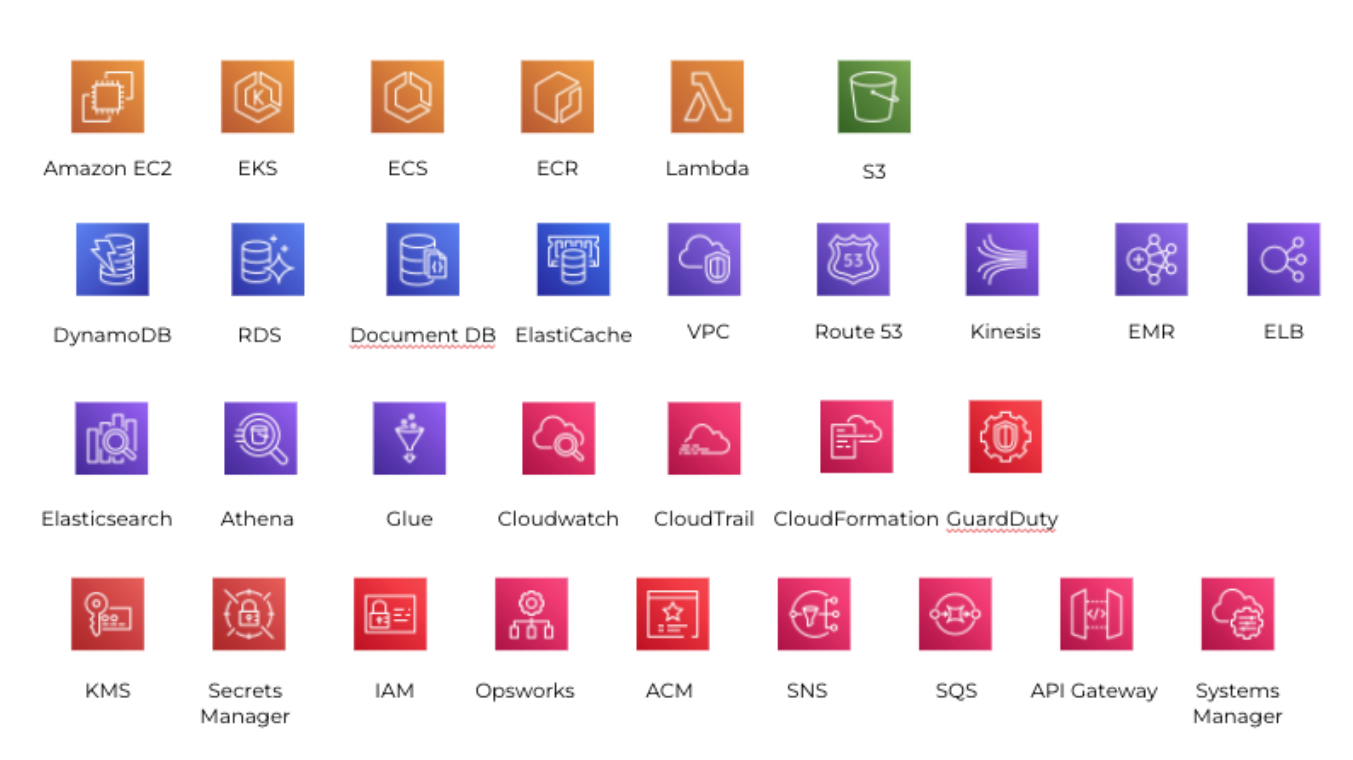
In addition to the increase in AWS resources, internal resources are also rising sharply as our business scales. Managing a diverse and exploding number of resources is probably a challenge for other companies as well.
Infrastructure engineers will continue to manage a growing number of new resources. The current infrastructure may also completely change due to architectural issues. We may employ and manage external resources to address any issue.
Before handling the “large-scale infrastructure” we are familiar with, we usually run a small service type on the server and manage it by shutting it down. We do have a general design, but we repeat startups and shutdowns through trial and error.
The infrastructure will become more consolidated after making iterative adjustments to our application. We usually start scaling our infrastructure for business purposes once we reach this point.

Although similarities may be found in the previously consolidated infrastructure, infrastructure resources may be added, modified, or deleted to answer customer requests and requirements for business reasons. In order to satisfy various needs and respond to unexpected changes, infrastructure engineers have to keep the following in mind and try varying measures.
- The infrastructure should be flexible to changes.
- Observability should be secured to track the resources.
- We should look for cost-effective methods.
- We should think about how we can establish a security policy.
Fulfilling all of these items would be a dream for every infrastructure engineer, but the reality isn’t all that rosy. Issues are common, and incidents break out from nowhere.

However, according to my experience and quotes from some of my fellow engineers, “Reality is often not ideal, but infrastructure engineers make it so.”
Sendbird’s past infrastructure
Time of upheaval
In the past, Sendbird’s infrastructure used CloudFormation to create resources to build a huge infrastructure in an isolated environment. Resources were not made in the CloudFormation console and were Jinja templated instead. And using an in-house solution operated by our team, we created and distributed YAML files with templates and configurations.
However, there were several issues and challenges before creating a single isolated environment.
Tightly coupled architecture
A tool called Magpie creates infrastructure with CloudFormation templates and application configuration values. Therefore, updates had to be made immediately upon configuration value or CloudFormation template changes.
Moreover, to carry out such actions, the magpie code had to be updated as well. So if there were any failures, we had to verify whether the configuration was set correctly, the CloudFormation templates were updated, the magpie tool accepted them, and there were no problems during execution.
We also had to troubleshoot every time updates were made, making it very stressful.
Endless configuration
We would have been very fortunate if all of the isolated environments were set up with CloudFormation, but as non-AWS resources increased, we had to create those resources one by one. And when documenting the process, we had to rely on human memory and recall the time and situation of the setup.
Resource management based on human memory
Resource changes can be made through the AWS console after an unexpected failure or if needed. However, it is impossible to reflect such changes to the CloudFormation template immediately. Also, there is a delay since several engineers are working on this issue instead of one. Eventually, the items requiring changes accumulate to a point where they cannot be updated anymore and forces us to rely on human memory.
When we identified those issues, many tasks were stuck. I wanted to address the working procedures and problems.
Rather than relying on human memory and doing manual updates, we wanted to create a work environment with both infrastructure and documentation features and update the infrastructure only when the code changes.
Sendbird’s infrastructure today
Why IaC? Why Terraform?
While building the infrastructure then and now, there is a principle we wanted to hold to: “the code comes first.”
Even if people are making changes to the infrastructure, the code takes precedence, so we should re-implement or update the code to align it with the infrastructure. We changed the IaC tool from CloudFormation to Terraform because it was suitable for implementing the principle and several advantages below.
The first advantage is seeing the results before running a dry run. Resources are not created immediately, but we can see how they are created or changed before execution by referring to the dry-run result.
The second is a state file, by which you can compare the current code with the actual resources that were affected. Its file type is JSON, and when applied through Terraform, a Terraform state file is generated for every resource created. Terraform compares the state file to the resources that exist in AWS. The state file can be uploaded to the S3 bucket or used as a local file. And the state file has a lock feature that prevents multiple people from working on the same infrastructure simultaneously.
The third is a provider that can convert various product groups into IaC. Previously, we had to set up non-AWS resources after setting up all of the isolated environments. Typical examples include PagerDuty for receiving alarms, DataDog for monitoring, and Spinnaker for distribution. These can be set up with the providers provided by Terraform.
Re-usable module
There are several resources required to create an isolated environment.
So, we used the following major modules as basics and built a big core module by collecting various modules and resources.
- VPC module: vpc, subnets, Internet G/W, NAT G/W, routing table for the network layer, one bastion server (required), and VPC as a group.
- EKS module: In order to build a Kubernetes cluster, we group cluster, oidc provider, nodegroup, IAM role for the controller, policy, etc., as an EKS module.
- Server group module: Resources related to instances such as ASG and LB can be used separately or combined as needed, and they belong together in a server group module.
Modules should be implemented so that they can be reused in numerous places. And you need to design and implement a decent abstract module so that the flags and variables that are required externally can be injected.
Modules that are designed as below have their own version, and users only need to use the version they need. Externally, you only need to trust and use the key version, and you do not need to know the detailed internal configuration to manage them at all.

If the modules are ready, we can now make a new isolated environment. We only need to specify the versions of the core module v1.0.0 above and the required modules.
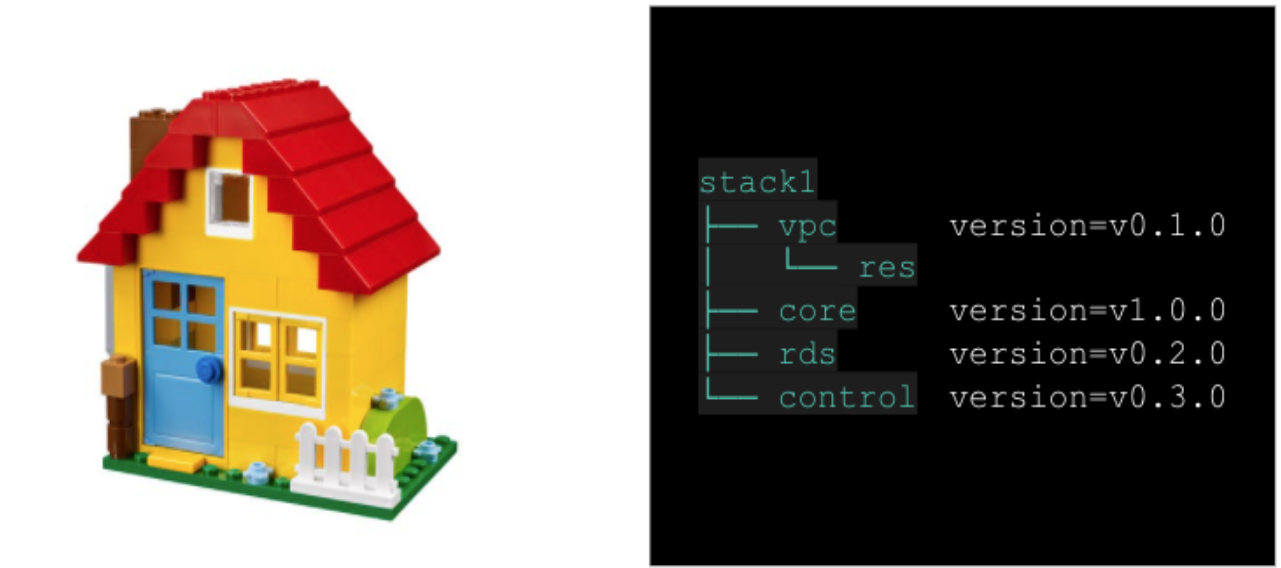
Next, how can we make more isolated environments? It’s fairly simple. You only have to copy and paste the module code as seen in the picture below and change the variable values as needed externally.
If you need resources that are not from modules, you can inject the created code on the same level as stack.
Apply with automation
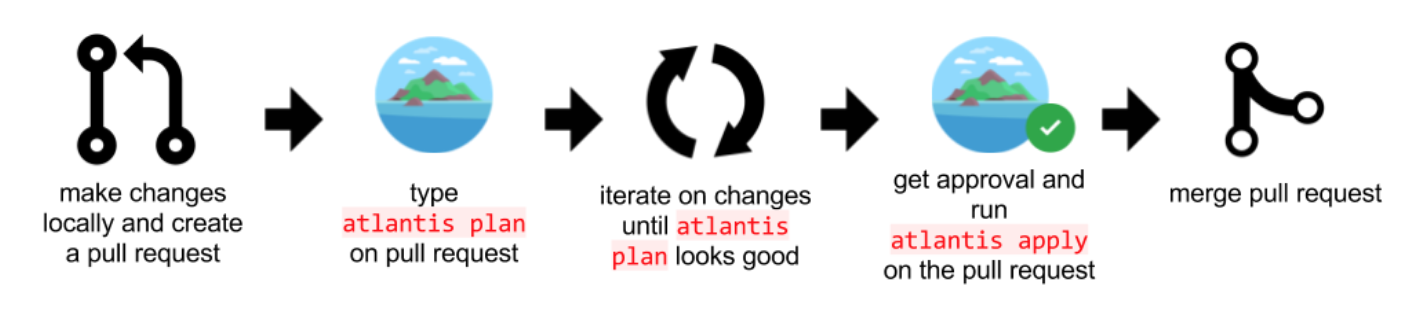
Now the code is ready. We commonly use a command called terraform plan & apply it to reflect the prepped code to the actual environment. We check the dry run results with plan and proceed to reflect it with apply.
However, these steps are not done in the local environment.
First, make a PR (Pull Request) to the repository where you will prepare the code.
Second, receive the dry run result with the Atlantis plan command using a pull request automation tool called Atlantis, then send it for review.
Third, reflect the actual resources with the Atlantis apply command once you have approval. Once complete, this will trigger two events.
- Uploading the JSON file 'tfstate’ containing a list of applied resources to S3.
- Creating the resources specified by code.
Fourth, once the reflection is done, the PR will be merged.
Infra testing & provisioning
We used reusable modules to create a single isolated environment multiple times. Now, if a new resource is added to a module, how do we validate it?
Review and deployment are done in 3 separate phases: Development/Staging/Production. First, we upgrade and apply the module version with the new resources in the Development environment. At this step, we thoroughly check what resource changes there are and whether there are any major changes when we go to Production. This is because the changes caused when applying a new module version to the production environment should be minimized.
After confirming the change in the development environment, apply it to the staging environment and check whether there are any problems in the applications. After applying the module upgrade in the staging environment, we run test cases for the applications to check whether there are any problems in the staging environment. We capture the issue and quickly roll back to the original module to identify the cause if there is a problem.
After verification is complete in the Development and Staging environments, we carry out the deployment to the Production environment. Likewise, we capture the problem and then quickly roll back to the original module to figure out the cause if there are any issues.
What was the impact?
Many things changed after we started managing the infrastructure with Terraform.
- We were able to decouple the tightly linked infrastructure and application.
- The infrastructure creation velocity is faster than before. Previously it would take at least a week to track the history and write code, but today we can prep and apply the infrastructure code in a day.
- Without verbal communication, our team members can track and update the infrastructure changes solely with code. This positively impacted our productivity.
The way ahead for our infrastructure
The infrastructure team should make efforts to shape the code so that all isolated environments are aligned to the same shape whenever possible. In addition, we plan to prioritize codes and apply them to the infrastructure with a “code comes first” attitude in mind. Since we deal with multiple isolated environments rather than a single one, we hope to find an automated measure to ensure that code updates are consistently applied.
In addition, although I didn’t cover this earlier in this post, each module must pass the test code to generate a release version. We will create test codes for all modules to respond flexibly to various environments and external changes.
Fulfilling all of these items would be a dream for every infrastructure engineer, but the reality isn’t all that rosy. Issues are common, and incidents break out from nowhere.





