Building Sendbird: On-device caching on unreliable networks

Introduction
This is the first in a new blog series, ‘Building Sendbird’, from the Sendbird Engineering team, where we’ll outline the hard-won lessons learned from years of building the platform that supports high-scale global apps such as Reddit, Hinge, Paytm, Delivery Hero and Teladoc.
We’ll be regularly publishing new posts over the coming months that will give insights into a particular aspect of how we’ve built our chat platform to support more than 150 million monthly active users.
First up: Chris Heo, a Software Engineer on our messaging SDK, writes on the challenges of delivering on-device caching on unreliable networks.
Many of our customers’ end users experience poor internet connections. This is especially the case in certain geographies with unreliable internet infrastructure. At Sendbird, we build for a global scale, so we wanted to ensure that all end users—even those with slower or intermittent chat connections—have the best possible chat experience.
This post outlines the technical details of this challenge, and how our engineering team approached building a solution. Read more to learn how we:
- adopted local caching as a method to give users an “offline mode”
- optimized the speed of updates to chat content
- ensured the integrity of chat content in conversations.
Background: On-device caching for asynchronous apps
Before diving into the specific technical challenges we tackled at Sendbird, I’d like to provide some context on on-device caching for asynchronous apps.
Caching content on the local device is a common technique that enables an app or web page to instantly show a fully functional view of the content when it’s opened, without having to do a slow round trip to the server. Additionally, many operations such as searching can be performed locally without incurring the latency hit of talking to the back-end server.
When designing an application that has to deal with unreliable network connections, such as phones that are jumping between network towers while traveling, or only having a data connection available when WiFi is available, on-device caching is crucial for allowing the app to remain useful even without data access.
Creating a seamless user experience that allows for all of this while dealing with asynchronous network events creates a number of unique challenges, below we’ll list some of the challenges we’ve faced and the solutions we’ve developed to address them.
The engineering challenges
Designing for unreliable networks
One significant challenge we faced was that many end users have unreliable internet networks. Asynchronous operations are particularly affected by network disconnects as there’s no easy way for the app to know if any messages were lost.
First, we established the following design criteria for desired behavior during normal operations.
When the network is operating normally:
- Messages should be shown in chronological order.
- New messages could arrive at any time.
- A user’s view could be anywhere in the process—the most recent messages, the position the user left off, or a search result.
- Fetch messages from the server whenever possible.
Next, we’ll outline how to address exceptions, such as when a user loses service.
Exception handling
There are a range of things that can go wrong if the user loses service or the server is down. We needed to account for the following exceptions:
- New messages could be missing due to temporary network loss.
- A user may notice that some messages are missing, but these will be filled in as the network recovers. Once it does these messages will be inserted into the view so it’s eventually consistent again.The app should work even if it is in the background or the internet connection is slow or disconnected. When it comes back to the foreground or the connection returns, the cache should start fetching anything that was lost.
- As the number of missed messages could be large, the right solution should be as efficient as possible for both the client and server.
Additional limitations
Beyond the above, there were some additional limitations we needed to design for:
- A missing message ID doesn’t always mean that there’s a missing message. Moderation filters, users deleting messages, and other similar actions can remove a message ID from the list without it meaning that there was a network error. Given a list of messages with ID 1..100, if you apply a message type filter, then the list could be a sparse array that doesn’t contain any not matching the filter.
- The code complexity and its operation should be easily understandable and elegant enough to reduce both the maintenance costs and the potential for bugs.
- Cache I/O could fail.
The solution: Designing a cache that resolves these characteristics
Defining inputs and outputs
We’ve started by defining the input data and the expected output state because they establish the entry point for the build. The input data in a chat service includes:
- Real-time message event (the device is connected)
- Messages fetched through an API request (when the online device connects to the server to retrieve messages)
- Messages read from cache
We assume that the messages fetched via an API request have no missing messages because the server guarantees them to be continuous. The cached data, on the other hand, has no boundary information itself to guarantee the continuity of messages, and the real-time message could also be missing due to packet loss.
The expected output is the list of messages with no missing entries. It could take time to generate the result because all of the input comes asynchronously (mostly through the network transaction which is very costly in terms of time) and it has to deal with common problems associated with a multithreading environment.
As the input and the output appeared to get arranged correctly, we proceeded to the next step: designing the process based on the input, output, and the given requirements.
Adopting time-stamp-based ranges
Initially, we considered using the timestamps to determine the range of data that is already available, and what new data comes in through the API call. Every time the API response gives the messages, the range of the messages is appended to the currently available ranges. Figure 1 shows how this time-stamp-based ranging works.

By using the timestamp-based ranges, we could determine if there were any missing messages. However, there are some drawbacks with range management.
- Storing the range adds another asynchronous operation so it increases complexity.
- Integrity could be broken if the range and the messages don’t match to each other.
Collectively any differences between the known messages and the time stamps of new incoming messages could cause some mismatches in the data, especially when that data is processed asynchronously in multiple parallel requests. In order to reduce the impact, we minimized range management by range interpolation.
Gap detection and patching
The goal is to always show a complete list of messages without any gaps, however, this does come at a cost as we covered in the previous section. So as an alternative, we implemented a gap detection and patch process.
This process fetches messages from the cache and the server separately on initialization. There could be a gap between these, so the system tries to detect these gaps and fill it through a series of API requests for these messages. The most common scenario to illustrate this is to enter a channel which has a larger number of messages that were sent since the user had last participated then what is fetched in the default new message API call. Figure 2 shows how the gap patch works in this case:
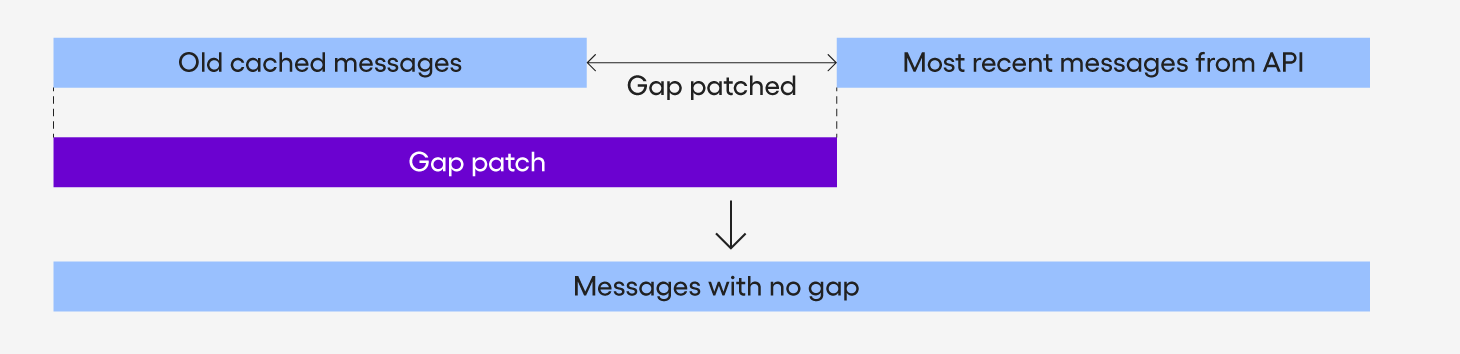
Because this process doesn’t manage the synced ranges, we can assume that there’s no gap in the range of the old cached messages. So the gap patch fetches multiple blocks of messages until it reaches the edge of the old cached messages.
With gap detect and patch, we achieved greater flexibility in showing messages without range management. By adopting the gap patch:
- Synced ranges don’t have to be stored to cache or managed.
- Contrary to synced ranges, which should extend themselves continuously, a gap patch only runs when the gap is detected.
Unfortunately, we still have a problem with gap detection and patching. There could be a gap that is quite large—more than 1k+ messages — where the gap patch is an expensive operation. So, we needed a solution for handling large gaps.
Large gap handling
Large gap scenarios happen infrequently as each individual chat room usually won’t have huge amounts of messages per second, but it is still an important edge case to ensure the best customer experience and deal with scenarios such as high message/second peaks in a channel during live events. Looking at the scenario in Figure 2, we could pick among three possible approaches in this situation:
- Fill the gap anyway.
- Clear old cached messages from the view. Only messages from the API are shown.
- The old cached messages stay and discard the messages from the API.
Because it’s rare, clearing the view is the best way to handle this. But we’d also add some options to switch the operation by the customers.
Offline mode
Last, the offline mode matters because the cached data could be shown with no internet connection. Another thing to consider is the recovery process when the connection is restored because it simply shows the cached messages on offline status. The problem arises when it’s back online. The messages that are shown may have some gaps during offline status so the recovery must fill the gaps. Fortunately, turning to online status triggers the gap patch operation for the recovery.
What we’ve learned from building local caching
Local caching poses some particularly thorny engineering challenges, and we hope we’ve given your greater insight into the technical challenges that we’ve tackled while building a reliable chat infrastructure at Sendbird, and also given you ideas about some approaches for tackling caching and synching in your own environments.
The journey was a challenge for our team over the past few years, and required various trade-offs and difficult technical decisions. However, we’re proud of the stable and sound caching architecture that delivers the best possible experience for our customers in all network conditions. This especially benefits end users in geographies where network quality may be inconsistent, enabling us to serve a truly global audience.