What is RAG (Retrieval Augmented Generation)? Enhancing AI agent LLMs with dynamic information access


What is RAG?
Retrieval-Augmented Generation (RAG) is a technique in large language models (LLMs) that enhances responses by retrieving relevant information from an external knowledge base before generating an answer. This approach combines retrieval methods with generative capabilities, allowing the model to provide more accurate, context-rich answers. RAG is particularly useful for tasks requiring up-to-date or domain-specific knowledge.
RAG is especially useful for AI support agents. For example, AI agents enhanced with RAG might be able to tap into a knowledge base (external to the AI agent LLM it has been trained on) of specialized company data to answer specific employee questions related to onboarding, IT support, or finance. A RAG-enhanced AI concierge can access company knowledge of policies and procedures while answering customer service or support questions.
This blog provides a comprehensive overview of Retrieval Augmented Generation (RAG), walking through the process of building a high-performing RAG system from the ground up. In this blog, we’ll explore core RAG concepts and delve into our unique methodology of evaluating and improving RAG quality. We’ll also share advanced techniques for reducing hallucinations and maximizing response accuracy. This in-depth exploration culminated in the development of Sendbird’s AI agent, which leverages these very techniques to achieve industry-leading performance.

8 major support hassles solved with AI agents
Why is RAG important?
In a nutshell, RAG is important because it allows Large Language Models (LLMs) to access and integrate specific, real-time information, overcoming limitations of static knowledge and improving response relevance and accuracy. By retrieving up-to-date or specialized content, RAG reduces the model's reliance on generalized training data, enhancing its effectiveness in tasks like summarization, answering specialized questions, and knowledge-intensive applications. This approach supports greater model scalability and adaptability across various domains. RAG ultimately boosts the model’s utility for real-world applications, especially in rapidly evolving fields.
A deeper dive into the importance of RAG
Large Language Models (LLMs) like GPT, Llama, and Claude have transformed the landscape of artificial intelligence in language-related tasks. These advanced LLMs demonstrate exceptional capabilities in text generation, and can process diverse types of information and respond to a range of queries with impressive accuracy. This versatility enables these LLMs to function across numerous domains, from ecommerce and customer service to healthcare and real estate.
LLMs are typically good at:
Natural Language Understanding (NLU) and generation: Understanding context in human language and producing appropriate responses. This is especially important for AI customer service agents.
Information synthesis: Combining information from multiple sources to answer complex queries or provide explanations. This can be used in customer support with Salesforce.
Language tasks: LLMs are good at summarization, translation, and text completion.
Creative writing: LLMs can generate stories or other creative content based on prompts.
However, LLMs have some limitations because their knowledge is fixed at the time of training:
Limited knowledge of recent events: LLMs lack information on current global affairs, political developments, and breaking news.
Inability to provide real-time data: LLMs cannot access or report on dynamic information, such as current market rates or live statistics.
Absence of organization-specific information: LLMs do not possess knowledge of internal corporate policies, procedures, or proprietary data unique to individual companies.
No access to private or confidential data: LLMs cannot retrieve or process information from closed meetings, internal communications, or secure databases.
Retrieval-Augmented Generation (RAG) helps solve these problems by giving LLMs access to up-to-date information. RAG was introduced in 2020 by researchers from Facebook AI (now Meta AI). RAG combines the strengths of pre-trained language models with the ability to fetch and use relevant information from external sources. This helps LLMs generate more accurate, current, and specific answers, especially for tasks that need recent or specialized information.
How RAG works: RAG architecture
RAG keeps a database of external information. When someone asks a question, the system finds the most relevant documents from this database and adds them to the original question. The LLM then processes this expanded question, allowing it to give more accurate answers based on both its pre-trained knowledge and the added data.

For example, an IT support AI agent enhanced with RAG could handle complex troubleshooting questions by retrieving specific internal documentation or recent support tickets. For instance, if an employee asks, “How do I resolve a network connectivity issue with the company VPN?” the RAG-enabled agent would first search its database for recent VPN troubleshooting guides, relevant FAQs, and recent incidents with similar issues. After retrieving and appending this information to the original query, the LLM processes it, providing a more tailored, up-to-date answer, such as guiding the user through step-by-step VPN reconnection processes based on recent solutions. This approach helps ensure the AI agent's responses are both accurate and aligned with the company’s latest IT practices.

Anywhere, anytime AI customer support
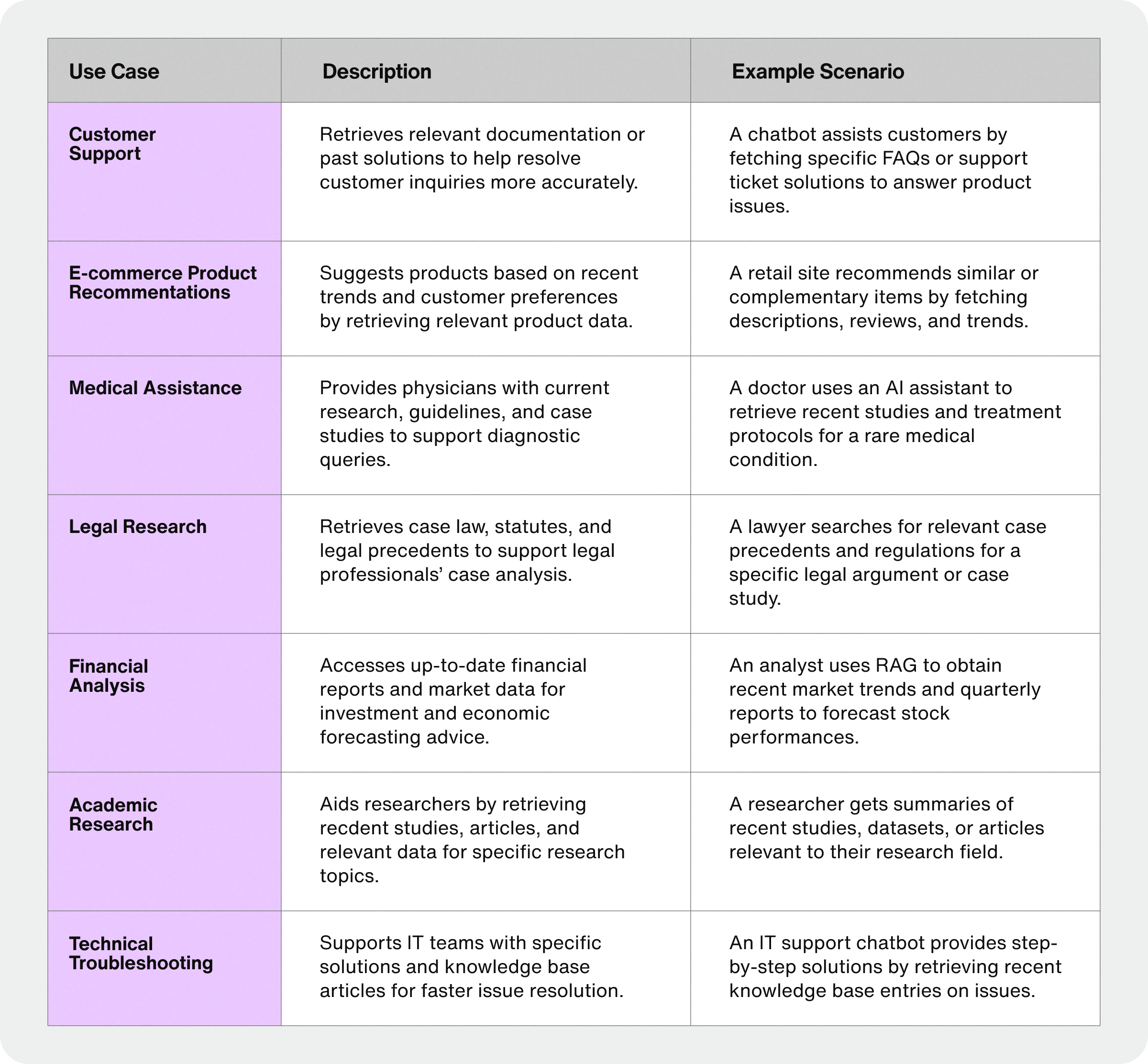
Top 7 RAG use cases
RAG can be used in many ways - your creativity is the limit. Here are the top 5 most popular RAG use cases:
Top 4 benefits of RAG: Why RAG is indispensable for AI agents
With RAG, an LLM’s capabilities are greatly enhanced:
Gaining knowledge of recent events: LLMs can discuss current affairs by accessing the latest news articles.
Providing real-time data: LLMs can offer up-to-date information by checking real-time financial databases, allowing them to provide current exchange rates and market information.
Incorporating organization-specific information: Through RAG, LLMs can provide company-specific policies by accessing internal documents and ensuring their responses align with the organization's up-to-date practices.
Handling private data: RAG enables LLMs to reference confidential internal documents while maintaining security protocols, providing LLMs access to sensitive information in a controlled environment.
Retrieval-Augmented Generation represents a significant advancement in the capabilities of Large Language Models. By bridging the gap between pre-trained knowledge and up-to-date, specialized information, RAG enhances the accuracy, relevance, and applicability of LLMs across a wide range of use cases.
The integration of RAG into LLM systems opens up new possibilities for businesses and organizations. It allows for more dynamic, context-aware AI assistants that can provide current information, adhere to the latest policies, and offer insights based on the most recent data available. This makes RAG-enhanced LLMs particularly valuable in fast-paced environments where information currency is crucial.
At Sendbird, we've harnessed the power of Retrieval-Augmented Generation to enhance our customers' AI agent experiences. By implementing RAG in our AI agent platform, we enable businesses to create more intelligent, up-to-date, and context-aware conversational interfaces. This means that AI customer service powered by Sendbird can access and use the most current company information, product details, and customer data in real time. As a result, our customers' AI agents can provide more accurate responses, offer personalized recommendations based on the latest offerings, and stay aligned with the most recent company policies and guidelines.

Delight customers with AI customer service
Now let’s discuss the technical aspects of RAG in more detail.
The technical core of RAG
Having explored the fundamentals and applications of Retrieval-Augmented Generation (RAG), let’s now turn our attention to the heart of this technology: the retrieval mechanism. This critical component is responsible for querying and extracting relevant information from a knowledge base to augment the language model's output.
Retrieval models in RAG
The retrieval mechanism in RAG primarily uses two categories of models: traditional sparse vector models (including keyword search techniques) and more recent dense vector models. Each has distinct characteristics that make it suitable for different use cases.
Sparse vector models and keyword search
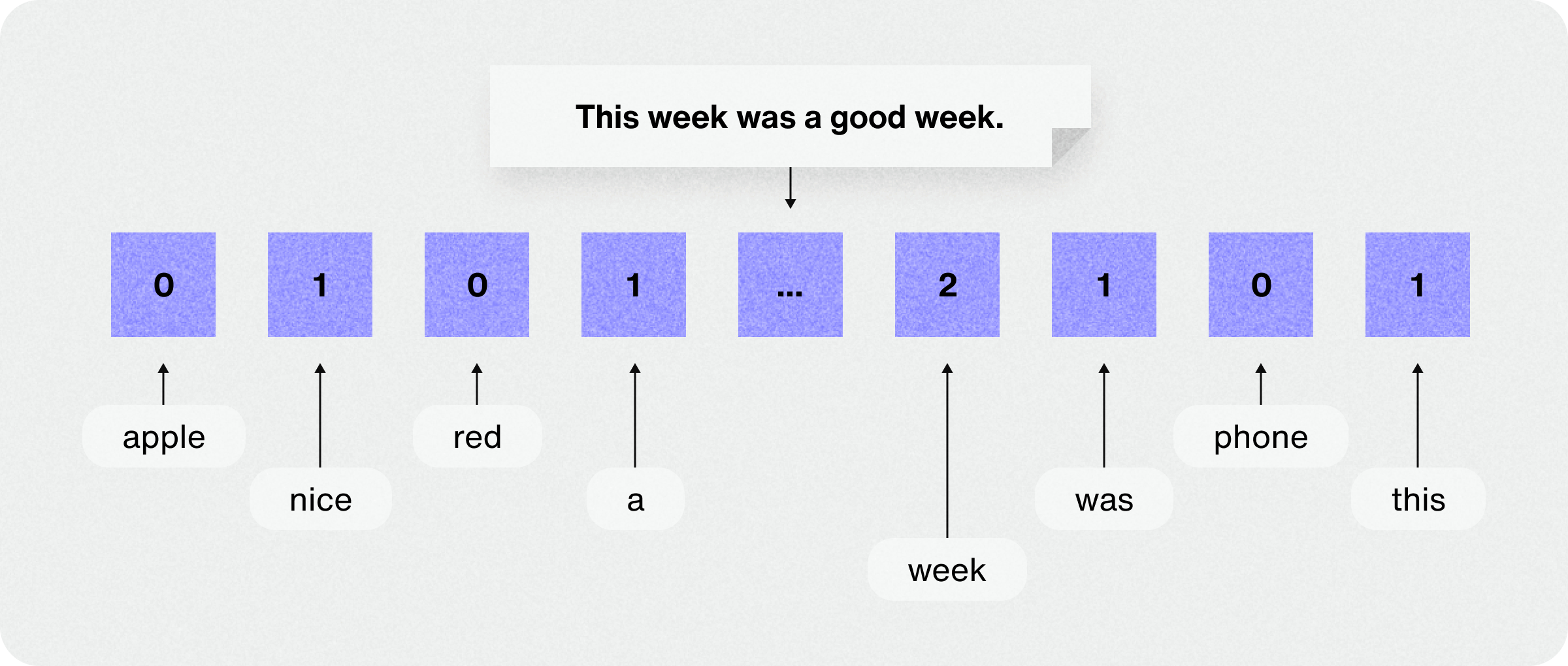
Sparse vector models, including traditional keyword search techniques, have long been fundamental to information retrieval systems. These models represent documents and queries as high-dimensional vectors with mostly zero elements, hence the term "sparse."
These vectors, which typically represent the presence or absence of words in a document or query, often contain many zeros due to their construction method. Given that any single document or query uses only a small portion of all possible words in a vocabulary, most vector elements are zero.
Consider a vocabulary of 100,000 words. A typical document might contain only a few hundred unique words. This results in a vector where over 99% of the elements are zero, effectively illustrating the "sparse" nature of these representations.
One of the most popular and effective sparse vector models is BM25 (Best Match 25). To understand BM25 and sparse vector models in general, it's helpful to start with the foundation of keyword search and the concept of TF-IDF (Term Frequency-Inverse Document Frequency).
Let's break down some key concepts:
TF (Term Frequency): This measures how often a word appears in a document. If a word appears many times in a document, it's probably important to that document's topic. For example, if the word "cat" appears 10 times in a short article, that article is likely about cats.
IDF (Inverse Document Frequency): This measures how unique or rare a word is across all documents in a collection. Words that appear in many documents (like "the" or "and") are less informative than rare words. IDF gives more weight to words that appear in fewer documents.
Ranking Documents using TF and IDF: To rank documents, we combine TF and IDF into a single score called TF-IDF. For each word in a search query, we calculate its TF-IDF score in each document. The score is higher if the word frequently appears in the document (high TF) and is rare across all documents (high IDF). By summing these scores for all query words in each document, we can rank documents based on their relevance to the query.
Building upon this TF-IDF foundation, BM25 introduces additional refinements. It uses a probabilistic approach to evaluate and rank document relevance, incorporating elements like document length normalization. This helps balance the relevance scoring across documents of different lengths, providing more accurate and nuanced search results.
Let's look at a concrete example of how a sparse vector model like BM25 would process a query:
Sample query: "What are the best practices for creating strong passwords?"
1. Query processing:
The query is tokenized, and stop words may be removed:
Unset
["best", "practices", "creating", "strong", "passwords"]
2. Inverted index lookup:
The system looks up each term in the inverted index:
Unset
"best" -> [doc1, doc3, doc7, ...]
"practices" -> [doc2, doc3, doc5, ...]
"creating" -> [doc1, doc4, doc6, ...]
"strong" -> [doc2, doc3, doc7, ...]
"passwords" -> [doc2, doc3, doc5, ...]
3. Scoring:
For each document that contains any of the query terms, BM25 calculates a score. Let's say we have a document (doc3) with the following content:
"Creating strong passwords is crucial for online security. Best practices include using a mix of uppercase and lowercase letters, numbers, and symbols."
BM25 would calculate a score based on:
How many query terms appear in the document
How frequently they appear
How rare these terms are across all documents
The length of the document
4. Ranking:
Documents are ranked based on their BM25 scores. Doc3 would likely receive a high score because it contains multiple query terms ("best", "practices", "creating", "strong", "passwords") and they appear in relevant contexts.
Dense vector models
Dense vector models, on the other hand, use neural networks to encode both queries and documents into dense vector representations. These models, often based on transformer architectures like BERT (Bidirectional Encoder Representations from Transformers), compute relevance between query vectors and document vectors using vector similarity measures such as cosine similarity.
At the core of dense vector models is the process of embedding, which converts words, sentences, or documents into numerical vectors. These embeddings are "dense" because most of their elements are non-zero, allowing for rich representations of semantic meaning. The transformer architecture, a type of neural network that has become dominant in natural language processing, is crucial to these models.
BERT (Bidirectional Encoder Representations from Transformers) is a prominent example of a dense vector model. It creates context-aware embeddings by looking at the context of a word from both directions - that is, the words that come before and after it in a sentence. This bidirectional approach allows BERT to better understand the meaning of words based on their surrounding context, enhancing the model's understanding of language nuances. To determine the relevance between queries and documents, these models often use cosine similarity, a measure of similarity between two vectors.
By leveraging these advanced techniques, dense vector models can capture semantic relationships beyond exact keyword matches. For instance, they might recognize that "physician" and "doctor" are related concepts, even if they don't share any characters. This semantic understanding is a significant advantage over traditional lexical models, allowing for more nuanced and context-aware information retrieval.
Let's see how a dense vector model would process the same query:
Sample query: "What are the best practices for creating strong passwords?"
1. Query embedding:
The entire query is passed through a BERT model to generate a dense vector representation, let's say of dimension 768. This vector might look something like this:
Unset
[0.1, -0.3, 0.7, ..., 0.2] (768 dimensions)
2. Document embeddings:
Each document in the corpus has been previously encoded into a similar 768-dimension vector. For example, doc3 might have an embedding like:
Unset
[0.2, -0.2, 0.6, ..., 0.3] (768 dimensions)
3. Similarity calculation:
The system calculates the cosine similarity between the query embedding and each document embedding. For doc3, it might look like:
Unset
similarity = cosine_similarity(query_embedding, doc3_embedding)
= 0.92 (high similarity)
4. Ranking:
Documents are ranked based on their similarity scores. Doc3 would likely receive a high similarity score because its embedding captures the semantic meaning related to password security practices, even if it doesn't use the exact phrase "best practices for creating strong passwords".
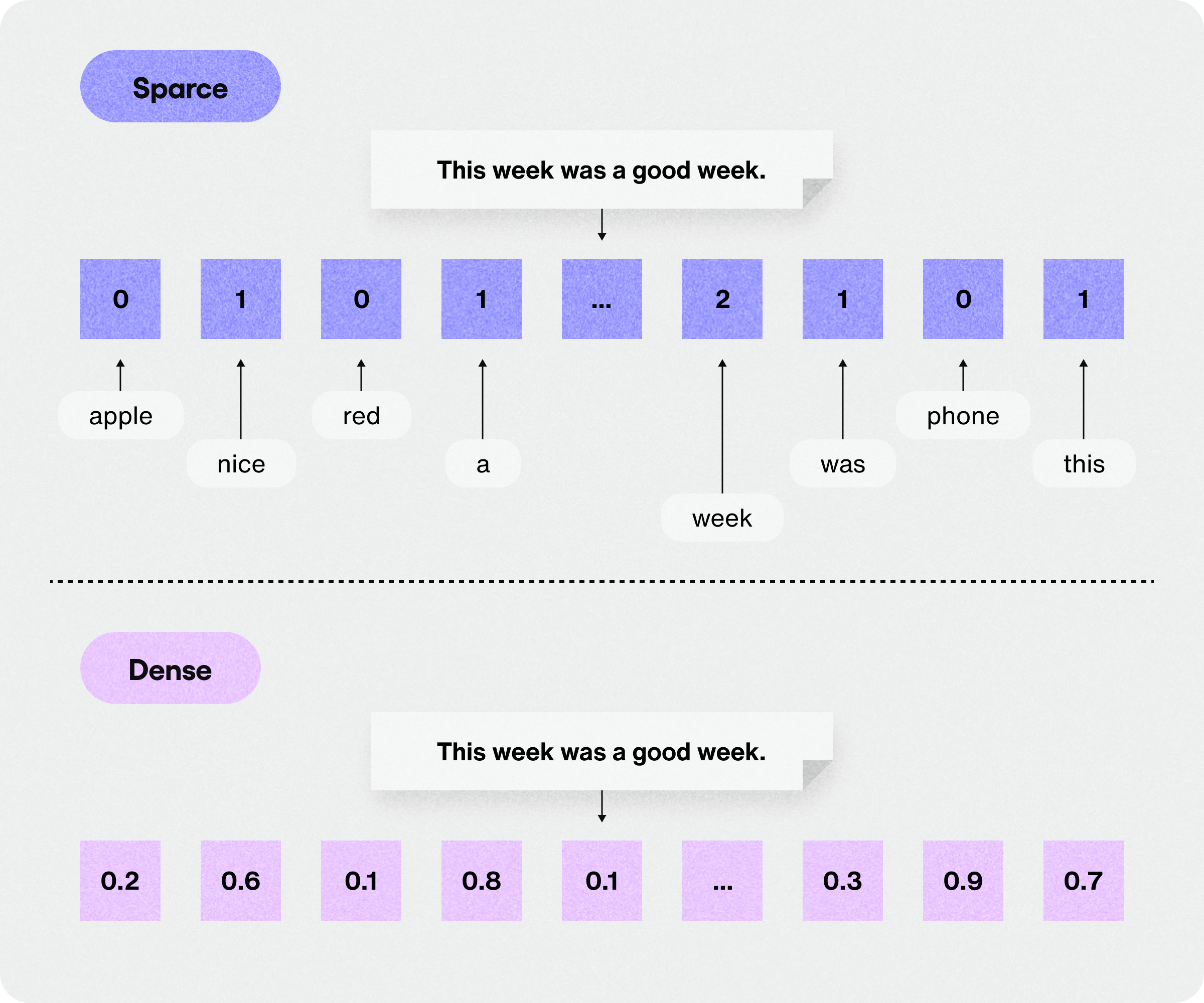
Key differences between sparse and dense vector approaches
We've explored sparse and dense vector retrieval models. Let's explore the key distinctions between these two approaches:
Semantic understanding: The dense vector model can understand that "creating strong passwords" and "secure password generation" are semantically similar, even though they don't share exact words. The sparse vector model relies more on exact matches.
Out-of-vocabulary words: If the query contained a rare word not in the BM25 vocabulary, the sparse vector model might struggle. The dense vector model can often infer meaning from context, even for unfamiliar words.
Computational complexity: The sparse vector model can quickly eliminate irrelevant documents using an inverted index. The dense vector model needs to compare the query vector with every document vector, which can be computationally intensive for large document collections.
Storage: The sparse vector model's inverted index is typically more space-efficient than storing dense vectors for every document.
Hybrid retrieval models
While both lexical models like BM25 and dense vector models have their strengths, there exist models that combine these techniques. These hybrid retrieval models aim to leverage the best of both worlds, offering improved performance across a wider range of queries.
A common hybrid approach uses a two-stage retrieval process. The initial stage employs a fast, lexical method like BM25 to quickly narrow down the document set. The second stage re-ranks the candidates using a more computationally intensive dense vector model. This captures semantic relationships and nuances potentially missed in the initial retrieval, enhancing overall result quality.
While this two-stage approach is effective, another strategy known as parallel retrieval offers an alternative method. In parallel retrieval, both lexical and dense vector searches are executed simultaneously. The results are then combined to produce a final ranking. This method capitalizes on the strengths of both approaches - finding exact matches and rare terms from lexical search and capturing semantic relationships and context from dense vector search.
When it comes to combining the results from these parallel searches, there are several strategies that can be used:
Score interpolation: Score interpolation involves creating a weighted sum of the lexical and dense scores, allowing for fine-tuned balance between the two methods.
Rank fusion: Rank fusion merges the ranked lists from each method, potentially giving more weight to documents that appear high in both lists.
Learning-to-rank: Learning-to-rank takes a more sophisticated approach by using machine learning models to optimize the result combination, potentially considering additional features beyond just the search scores.
Implementing a hybrid retrieval model often requires careful tuning to balance the strengths of different approaches. It also typically involves more complex system architecture, with potential trade-offs in terms of latency and computational resources. However, for many applications, the improved retrieval quality justifies these costs.
As RAG systems continue to evolve, we can expect to see even more sophisticated hybrid approaches that adapt dynamically to different types of queries and content, further blurring the line between traditional information retrieval and modern machine learning techniques.
Sendbird leverages hybrid search technology to enhance the performance of our AI agents, providing customers with more accurate and contextually relevant responses. By combining the strengths of lexical search methods like BM25 with advanced dense vector models, Sendbird's AI agent can handle a diverse range of queries effectively, from simple keyword-based questions to more complex, context-dependent requests.
As a result, Sendbird's AI customer experience platform offers improved response accuracy and a more natural conversational experience, ultimately leading to higher customer satisfaction and engagement for businesses.

Reinvent CX with AI agents
We’ve talked about what RAG is and how it works technically. Now, let’s discuss how to evaluate RAG systems.
How to evaluate Retrieval Augmented Generation (RAG) systems
RAG systems have changed how we approach Natural Language Processing (NLP). These AI systems are great at combining information retrieval and text generation, offering impressive capabilities in handling complex language tasks. However, figuring out how well these systems perform can be tricky because of their two-part nature. Let's explore the ways we can measure RAG systems' effectiveness, looking at both how they retrieve information and generate text, as well as why human evaluation is still crucial.
Checking retrieval quality
The retrieval part of a RAG system is key to generating accurate and relevant responses. When we evaluate retrieval quality, we typically use metrics that show how well the system can find and pull out the right information from its knowledge base. Two important metrics are precision and recall. Precision tells us what portion of the retrieved information is actually relevant, while recall shows how much of the total relevant information the system managed to find.
To get a single number that balances these two, we often use the F1 score. For a more comprehensive look across multiple queries, we use Mean Average Precision (MAP).
When the order of retrieved information matters, we turn to the Normalized Discounted Cumulative Gain (NDCG). This metric is particularly useful because it considers both how relevant the retrieved information is and where it shows up in the results list. It's based on the idea that users are less likely to look at results further down the list, so relevant information should appear near the top.
Assessing generation quality
Checking the quality of the generated text is just as important in evaluating RAG systems. We often use metrics originally created for tasks like machine translation and summarization, but it's important to remember that these aren't perfect for RAG systems.
BLEU and ROUGE are common metrics that compare word patterns to assess how similar the generated text is to a reference text. However, these metrics can sometimes be inaccurate when the response is correct in meaning but worded differently from the reference.
To address this, more advanced metrics like METEOR and BERTScore have been developed. METEOR is more flexible because it considers synonyms and different ways of phrasing things. BERTScore goes further by using contextual word meanings to compute similarity scores, giving a more meaning-aware assessment.
Perplexity is another metric worth mentioning. While it doesn't directly measure generation quality, it can give us insights into how well the model predicts and is coherent. Lower perplexity is generally better, but we should be careful about relying too much on this metric alone.
Why human evaluation of RAG systems is still crucial
Despite all these automated metrics, having humans evaluate RAG systems is still incredibly important. Expert reviews can catch things about accuracy, relevance, and coherence that automated metrics might miss. Getting evaluations from a larger group of people can also provide a broader view of how well the system is performing.
Other things to consider when evaluating RAG systems
When we're evaluating RAG systems, there are several other factors to keep in mind. How quickly the system responds and how efficient it is are crucial, especially if it's meant to be used in real-time. We also need to think about how well it can handle a growing knowledge base or an increase in the number of queries.
It's important to check if the system gives consistent answers to similar questions over time. We should also test how well it adapts to unexpected queries or new information to ensure its roobustness.
The system's ability to explain its sources or reasoning for its generated content is becoming increasingly important, especially in areas where transparency is critical.
In general, RAG systems require examining many different aspects, including retrieval and generation quality, human evaluation, and other performance factors. By using a comprehensive evaluation strategy, organizations can gain deep insights into how well their RAG system is performing, identify areas for improvement, and ensure the system meets the needs of its intended users. Regular evaluation and refinement are key to keeping RAG systems effective in real-world applications.
At Sendbird, we're committed to providing our customers with the best AI agent solutions. That's why we rigorously apply these evaluation metrics and methodologies to our RAG systems. By continuously assessing both retrieval and generation quality, we ensure that our AI concierges deliver accurate, relevant, and coherent responses. We combine automated metrics with regular human evaluations to gain a comprehensive understanding of our systems' performance.
This approach allows us to identify areas for improvement and quickly implement enhancements. Moreover, we pay close attention to factors like response time and scalability to maintain the high standards our customers expect. Through this dedication to thorough evaluation and ongoing refinement, Sendbird remains at the forefront of AI agent technology, offering solutions that meet and exceed our customers' evolving needs in the dynamic landscape of conversational AI.

Automate customer service with AI agents
Now, let’s talk about improving retrieval accuracy.
How to improve Retrieval Accuracy in RAG Systems
RAG (Retrieval Augmented Generation) systems have changed how we use AI for information retrieval and text generation. These systems are great at finding relevant information and using it to create accurate, contextual responses. They can work across many topics, handling different types of queries and data impressively well.
While the initial retrieval step is crucial in RAG systems, several methods improve the accuracy of retrieved results further. These techniques aim to ensure that the language model receives the most useful and relevant information.
Indexing and document processing
Enhancing text chunks with summaries
This technique aims to improve the quality of embeddings and search results by prepending summaries to text chunks before they are embedded. This method addresses a common issue in RAG systems: Individual chunks of text, when taken out of context, may lose important contextual information.
How it works
Text chunking: The document is first divided into manageable chunks.
Summary generation: For each chunk, a summary is generated that captures the main ideas and context of the chunk.
Prepending: The generated summary is then prepended to the original chunk.
Embedding: The combined summary and chunk are embedded together.
Top 3 benefits
Improved context: The summary provides additional context, making the chunk more self-contained and meaningful.
Better embeddings: The enriched chunks lead to more informative embeddings, potentially improving retrieval accuracy.
Enhanced relevance: During retrieval, the prepended summaries can help in better matching queries to relevant chunks.
This technique can be particularly useful when dealing with long documents or complex topics where individual chunks might lose important context when separated from the whole.
Query expansion and processing
Query expansion
Query expansion is a technique that broadens the initial query by adding related terms or synonyms. This can help capture relevant documents that may not contain the exact words used in the original query.
Synonym-based expansion
This method involves adding synonyms of key terms in the query. For example, a query about "cars" might be expanded to include terms like "automobiles," "vehicles," or "motors." This can be particularly useful when dealing with technical or domain-specific content where different terms might be used interchangeably.
Contextual query expansion
More advanced systems use language models to generate contextually relevant expansions. For instance, a query about "python" in a programming context might be expanded to include terms like "programming" or "coding." This method takes into account the broader context of the query to add relevant terms that might not be strict synonyms but are conceptually related.
SPLADE Model
The Naver SPLADE (Sparse-Dense Lexical and Expansion) model is an innovative approach that combines the strengths of sparse and dense retrieval methods. It's particularly relevant in the context of query expansion and can be considered a form of learned query expansion.
SPLADE uses a transformer-based architecture to predict important terms for both queries and documents. It produces sparse representations where each dimension corresponds to a term in the vocabulary. The model is trained to activate relevant terms, effectively expanding the original query or document representation.
Key features of SPLADE include:
Interpretability: The sparse representations allow for easy interpretation of which terms are considered important.
Efficiency: Despite being based on transformers, SPLADE can be as efficient as traditional lexical methods like BM25 during inference.
Automatic query/document expansion: The model learns to expand queries and documents in an end-to-end manner, potentially capturing complex semantic relationships.
SPLADE can be used as a standalone retrieval model or as part of a multi-stage retrieval pipeline, potentially replacing or complementing traditional query expansion techniques.
HyDE: Hypothetical Document Embeddings
Hypothetical Document Embeddings (HyDE) is an innovative technique that aims to bridge the gap between the query and potentially relevant documents by generating a hypothetical ideal document that would perfectly answer the query.
The HyDE Process:
Query analysis: The system analyzes the user's query.
Hypothetical Document Generation: Using a language model, a hypothetical document that would perfectly answer the query is generated.
Embedding: This hypothetical document is then embedded using the same embedding model used for the actual documents in the corpus.
Similarity Search: The embedding of the hypothetical document is used to perform a similarity search against the actual document embeddings in the corpus.
Benefits of HyDE
Query expansion: HyDE effectively performs an advanced form of query expansion by generating a full hypothetical document.
Bridging vocabulary gaps: It can help retrieve relevant documents even when they use different vocabulary from the query.
Contextual understanding: The generated hypothetical document can capture complex query intents better than the original query alone.
HyDE can be particularly effective for complex queries or in domains with a significant vocabulary mismatch between queries and documents.
Condensed Questions: Maintaining context in follow-up queries
Condensed Questions, also known as Standalone Questions, is a technique used to maintain context in conversational or multi-turn query scenarios. This method is particularly useful for handling follow-up questions that rely on previous context.
How Condensed Questions work
Context accumulation: The system keeps track of the conversation history.
Question condensation: When a follow-up question is received, it's combined with relevant information from the previous context to create a self-contained, standalone question.
Retrieval: This condensed question is then used for retrieval instead of the original follow-up question.
Example:
Original conversation:
User: "What are the top 3 programming languages for web development?"
System: [Provides an answer listing JavaScript, Python, and Ruby]
User: "Tell me more about the first one."
Condensed Question: "Tell me more about JavaScript as a top programming language for web development."
Benefits of Condensed Questions
Context preservation: Ensures that important context from previous interactions is not lost.
Improved retrieval: The condensed questions are more likely to match relevant documents in the corpus.
Better handling of ambiguous queries: Follow-up questions that might be ambiguous on their own become clear when condensed with previous context.
This technique is particularly valuable in conversational AI systems or any scenario in which users might ask a series of related questions.

Leverage omnichannel AI for customer support
Retrieval and ranking
Reranking: Refining retrieval results
After the initial retrieval step, whether using sparse, dense, or hybrid models, many RAG systems employ a reranking step to further improve the relevance of the retrieved documents. This step is crucial because it allows for a more nuanced and computationally intensive analysis of the relationship between the query and each retrieved document.
One popular approach to reranking is the use of cross-encoders. Unlike bi-encoders used in dense retrieval, which encode queries and documents separately, cross-encoders take both the query and document as input simultaneously. This allows for a more sophisticated modeling of the interaction between the query and the document.
Cross-encoders typically use transformer architectures like BERT, but instead of creating separate embeddings, they process the query and document together and output a single relevance score for the query-document pair. These scores are used to rerank the final documents.
The importance of reranking
The final reranking step plays a crucial role in optimizing RAG systems, particularly from a cost and latency perspective. After retrieving and reranking documents, we typically select only the top-N most relevant results (often just the top 3-5) to append to the language model prompt. This approach offers several significant advantages:
Reduced token count: By appending only the most relevant documents, we dramatically reduce the number of tokens sent to the language model. This directly translates to lower costs, as most LLM APIs charge based on the number of tokens processed.
Improved latency: Fewer tokens mean faster processing times. The language model can generate responses more quickly when it has less text to process, leading to improved system responsiveness.
Reduced hallucinations: By focusing on the most pertinent information, we increase the likelihood that the language model will generate accurate and contextually appropriate responses.
Optimized context window usage: Large language models have a limited context window. By being selective with the documents we include, we ensure that this valuable space is used efficiently, maximizing the relevance of the information provided to the model.
In essence, the reranking step allows us to balance comprehensive information retrieval and efficient, cost-effective operation. It ensures that we provide the language model with the most relevant context possible while minimizing unnecessary computational overhead and costs. This optimization is key to building scalable and economically viable RAG systems that can deliver high-quality results with minimal latency.
Build a powerful, RAG-enabled AI agent today
Enhancing retrieval accuracy in RAG systems is a multi-faceted challenge that often requires combining multiple techniques. The choice of methods depends on factors such as the specific application, the nature of the data, computational resources, and latency requirements.
By carefully selecting and integrating these enhancement techniques throughout the RAG pipeline, from document indexing to post-retrieval optimization, systems can significantly improve the relevance and usefulness of the information provided to the language model. This ultimately leads to more accurate and contextually appropriate generated responses.
The key lies in understanding the strengths of each method and how they can complement each other to create a robust and effective retrieval system. As RAG systems evolve, these techniques will play a crucial role in bridging the gap between large language models and external knowledge sources, enabling more powerful and context-aware AI applications.
At Sendbird, we are committed to leveraging cutting-edge Retrieval-Augmented Generation (RAG) techniques to provide our customers with highly accurate and context-aware AI support agents. Our systems employ a sophisticated combination of advanced retrieval and ranking methods to ensure that our AI agents deliver the most pertinent information to users. We continuously invest in research and development, actively exploring and implementing new methodologies to enhance retrieval accuracy and improve the overall performance of our AI-powered conversational experiences. By staying at the forefront of RAG technology, Sendbird ensures that our customers benefit from some of the most advanced and accurate AI agent platform available.
You can build your AI agent in minutes with our AI agent builder. 👉 Contact us to elevate customer engagement with the leading AI customer experience platform. We're here to help.








